
This page refers to a previous version of the add-in for Excel (2007 to 2016)
For Excel 365, use the lastest add-in version
Deep Categorization in Excel
The Deep Categorization analysis integrates the functionality provided by the Deep Categorization API, that is, assigning one or more categories to a text, using a very detailed rule-based language that allows you to identify very specific scenarios and patterns using a combination of morphological, semantic and text rules.
This is the interface that will appear when you click the Deep Categorization button:

As you can see there are two sections in the interface: Input, which we have already covered in the corresponding section, and Analysis Settings.
In Analysis Settings there are two values to select:
- Language, to select the language of the texts. By default, the language used in the last analysis will be preselected; in case it hasn't been set, the first element of the list will be the selected one.
- Model, with the model that will be used to categorize the texts. The models listed are determined by the language selected in the previous menu. In this list are also included any user-defined models associated to the key that's being used: they will be identified with a lock icon before the name, as follows:

Did you notice...?
All the resources that are part of any of our vertical or language packs appear with the cubes icon before the name. If you don't have access to them, make sure to request the free trial!
Advanced Settings
We've seen in the Settings section that there's an advanced settings menu with additional configuration options for the Text Classification analysis. These are the options available and their default value:

There are two main aspects to configure: the number of categories you want to see in the results, and which fields you want to output for each category.
- Number of categories shown: set by default to 10 and with a maximum value of 20.
- Fields:
- Code: shows the code associated to the category.
- Label: shows the label of the category; it's non-configurable, so it always appears in the results.
- Rank: shows the rank or order in which a category has been associated to a text.
- Relevance: shows the absolute relevance associated to the category.
- Polarity: shows the polarity of the category detected.
- Relative Relevance: shows the relative relevance associated to the category.
There's more information about each one of these fields in the response section of the API documentation.
Output
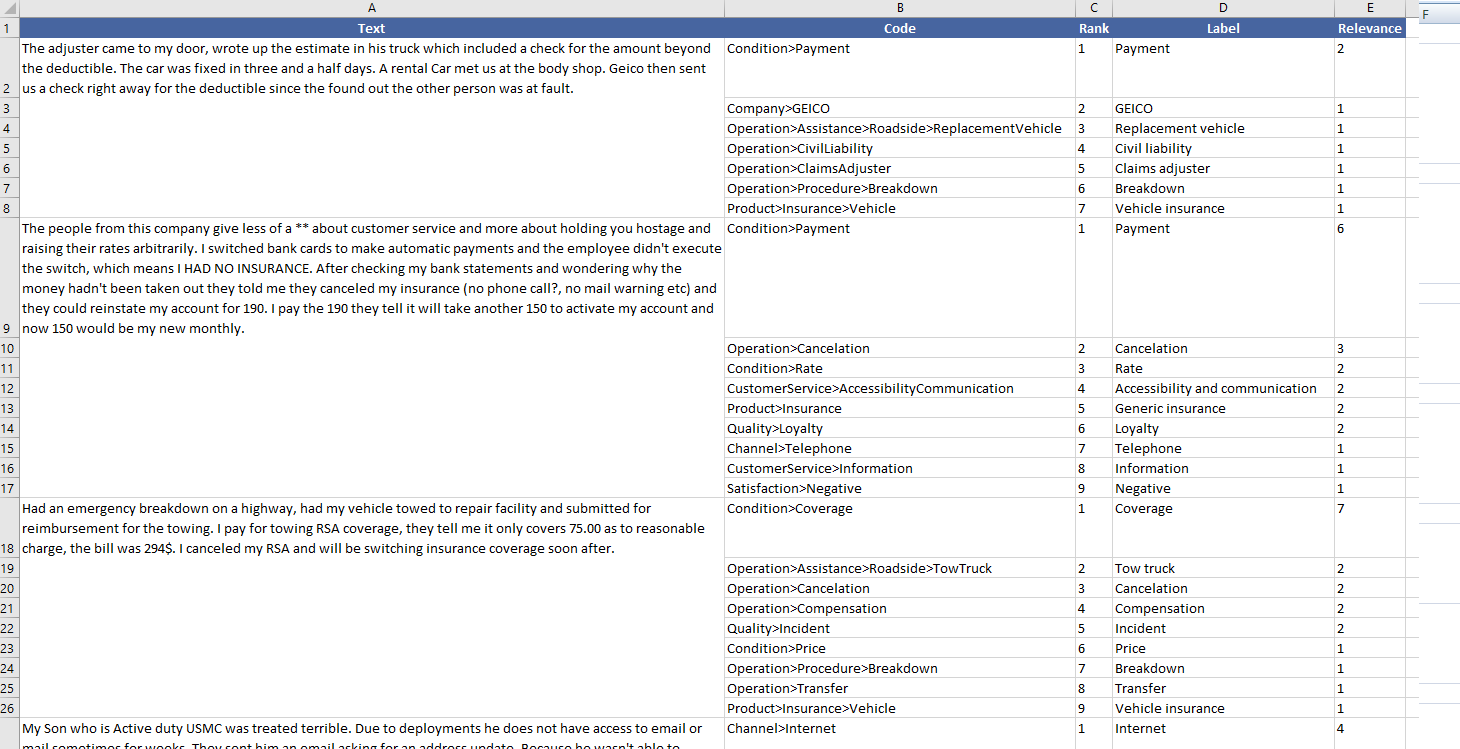
The results obtained from the categorization will be shown in a new Excel sheet called "Deep Categorization". This sheet will include a column with the source text, a column with the IDs if enabled, and then a column for each of the output fields configured in the advanced settings.
When the analysis is configured to output more than one category, each additional category associated to a text will be inserted as a new row, allowing a more flexible use of the results.
This is an example of a possible output of texts in English classified using the VoC model for the insurance domain and without using IDs. The configuration is set to show the output fields configured by default and up to 10 categories:
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2025 © All Rights Reserved | Data protection policy | Terms and conditions MeaningCloud is a a trademark by MeaningCloud LLC