
Response
The Lemmatization, PoS and Parsing API performs a deep analysis of a text, including syntactic and morphological analysis. The morphological analysis (Part of Speech tagging) includes lemmatization of each token of the text.
This API uses a complex structure to describe the elements analyzed, which we will refer to as tokens. It will be considered that a token representing the morphological analysis of a word corresponds to the token at the deepest level of its syntactic analysis. Or, in other words, the leaves of a syntactic tree will be the morphological analysis or PoS tagging.
The information provided is the same for the different output formats and the naming convention used for all fields is lowercase_separated_by_underscore.
The output contains information about the status of the request and about the complete analysis that has been requested. As it has already been mentioned, the basic element of these analyses is the token, which through different configurations will represent every possible node in a syntactic tree analysis.
The syntactic tree will have as many levels as the analysis requires. The first level will separate the sentences in the text and the lowest levels, the leaves of the tree, will be the basic elements: elemental tokens that will provide the morphological analysis where the PoS are assigned.
The following table shows the fields included in the response object.
PoS tagging and syntactic analysis output
| Name | Description |
|---|---|
status |
Contains information about the analysis process and whether it has finished successfully. It is formed by four different values:
Out of these four fields, You can find all the possible status codes returned by the API with an explanation and tips on how to manage them in our error codes catalog. A request is any HTTP request done to the API to analyze less than 500 words. If the text sent is longer than that, then it will be considered that more than a request is made, more specifically, as many requests as we would need if the text were divided in chunks of 500 words. For instance, an HTTP request with 1013 words, will count as three requests, so 3 Did you know...?Only the successful requests to the API will consume credits. In other words, the |
token_list |
List of tokens/units in which the input text is divided. Most of the time they correspond to words, but in some cases more than one word will be included in the same token. Each token will be represented by the object Check the token object to see in detail the fields in a |
global_sentiment |
Sentiment analysis information at a global level. This field includes:
The sentiment analysis information will be included in the response only when de |
Token object
The following table contains the fields that will appear in a token, and how we will represent each node of our morphosyntactic tree.
Token object
| Name | Description |
|---|---|
type |
Indicates which is the type of the token.
If no value appears, the token will be considered of the elemental type. Elemental types come from resources. |
form |
Form of the token. |
normalized_form |
Normalized form of the token. It will contain different values depending on what the token contains. The values will be identified by a prefix:
|
id |
Identifier of the token unique for the request and represented by a natural number. |
inip |
Initial position of the token, starting from 0. Tokens with |
endp |
End position of the token. Tokens with type sentence will always have 0 in this field. |
style |
This object contains information about the style of the text:
|
separation |
Describes how the token is separated with respect to the previous one. The possible values are the following:
|
quote_level |
Index that indicates the level of quote of an element. Currently only one level is supported. |
affected_by_negation |
If a |
head |
Identifies which child of the token defines its function by its token |
syntactic_tree_relation_list |
List of syntactic relations of the token. Each element is represented by the
|
analysis_list |
List with all the possible morphosyntactic analyses of the token. Each analysis will be represented with an |
sense_list |
List of senses or semantic analyses associated to the token. Each sense has four different fields:
|
sentiment |
Object that shows the polarity of the The sentiment analysis information will be included in the response only when de |
topic_list |
This element will show any topics associated to the token. The possible topics types that will appear are |
token_list |
List of children of a token. Elemental tokens will not have any children, so this field will only appear in non-leaf tokens. Each element will be a |
Sentiment element
The following table shows the different fields that will appear in the sentiment object.
Sentiment object
| Name | Description |
|---|---|
self_sentiment |
Sentiment analysis associated to this token. It's an object with the following fields:
|
inherited_sentiment |
Sentiment analysis affecting this token, but inherited from another one. This field is an onbject containing the following fields:
|
Syntactic Relations
These are the syntactic relationships detected and how they will appear in the type field of the syntactic_tree_relation element.
| isAgentComplement | isDirectObject | isNonAnaphoric | isRestrictiveApposition |
| isAnaphora | isIndirectObject | isNonRestrictiveApposition | isSubject |
| isAttribute | isLocationComplement | isPossessor | isTimeComplement |
| isComplement | isMannerComplement | isPredicative | |
| isCoreference | isNegationComplement | isQuantityComplement | |
In order to provide bidirectional relations, every single type will have its inverse version. This means that if token A is related to B through type, then B will be related to A through the inverse of type. The notation used for every inverse relation type will be and abbreviation of 'inverse of': iof_ + type. If A is related to B through the isSubject, then B will be related to A through iof_isSubject.
Analysis element
The following table contains the fields that will appear in an analysis, and how we will represent each node of our morphosyntactic tree.
Analysis object
| Name | Description |
|---|---|
origin |
Specifies where the analysis comes from, specifically if any additional techniques have been applied to find the analysis. The possible values are the following:
|
variety_dictionary |
Shows, in the cases where it applies, from which language variety dictionary comes the analysis. It only appears when it's not from the general dictionary or from a user dictionary (specified in the These are the possible values:
|
tag |
Morphosyntactic tag associated to the token. A detailed explanation of what every feature in each tag means can be found in the morphosyntactic tagset section. |
lemma |
Lemma associated to the analysis. |
original_form |
Original form of the token, that is, how it appears in the text. |
tag_info |
Explained values of the morphosyntactic |
variety_dictionary_info |
Expanded value of the language variety dictionary that appears in |
check_info |
Checker information associated to the token, which may include spelling, grammar and style errors and recommendations.
|
remission |
In the cases where the form is a variant of something else, this field will show the complete form. For instance 'cause will remit to because. |
sense_id_list |
List of sense identifiers, or in other words, list of semantic analyses associated to the morphosyntactic analysis. Each one will be tagged as a |
Semantic Information
In the string with semantic information the different attributes are separated by specific characters depending on the level of the type of information.
The characters that separate each level of information are:
| Level | Character | Description |
|---|---|---|
| 1 | \t | Separates first level attributes |
| 2 | / | Separates a complex attribute from its content (*) |
| 3 | | | Separates the different values associated to an attribute |
| 4 | @ | Separates the different attributes within a complex attribute |
| 5 | = | Separates the name from the value in simple attributes |
| 6 | # | Separates attributes associated to a simple attribute value |
| 8 | > | Separates hierarchy values within an simple attribute value |
(*) Except for the semld elements with URL format.
If the token has semgeo information associated, this info will appear in the language specified by ilang.
Response examples
The format in which this information will be shown will depend on the value of the of parameter.
The application has earned rave reviews from many major tech sites.
{
"status": {
"code": "0",
"msg": "OK",
"credits": "1"
},
"token_list": [
{
"type": "sentence",
"id": "15",
"inip": "0",
"endp": "66",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "A",
"quote_level": "0",
"affected_by_negation": "no",
"sentiment": {
"self_sentiment": {
"text": "*",
"inip": "0",
"endp": "66",
"tag_stack": "P",
"confidence": "100",
"score_tag": "P"
}
},
"token_list": [
{
"type": "phrase",
"form": "The application has earned rave reviews from many major tech sites",
"id": "23",
"inip": "0",
"endp": "65",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "_",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "Z-----------",
"lemma": "*",
"original_form": "The application has earned rave reviews from many major tech sites",
"tag_info": "clause"
}
],
"sentiment": {
"self_sentiment": {
"text": "The application has earned rave reviews from many major tech sites",
"inip": "0",
"endp": "65",
"tag_stack": "P",
"confidence": "100",
"score_tag": "P"
}
},
"topic_list": {
"relation_list": [
{
"form": "The application has earned rave reviews from many major tech sites.",
"inip": "0",
"endp": "65",
"subject": {
"form": "The application",
"lemma_list": [
"application"
],
"sense_id_list": [
"12fbb0dfc7"
]
},
"verb": {
"form": "has earned",
"lemma_list": [
"earn"
]
},
"complement_list": [
{
"form": "rave reviews from many major tech sites",
"type": "isDirectObject"
}
],
"degree": "1"
}
]
},
"token_list": [
{
"type": "phrase",
"form": "The application",
"id": "19",
"inip": "0",
"endp": "14",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "_",
"quote_level": "0",
"affected_by_negation": "no",
"head": "2",
"syntactic_tree_relation_list": [
{
"id": "14",
"type": "isSubject"
}
],
"analysis_list": [
{
"origin": "SEG",
"tag": "GN-S3S--",
"lemma": "application",
"original_form": "The application",
"tag_info": "phrase, nominal, singular, 3rd person, subject"
}
],
"token_list": [
{
"form": "The",
"id": "1",
"inip": "0",
"endp": "2",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "_",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "TD-SN9",
"lemma": "the",
"original_form": "the",
"tag_info": "article, determiner, singular, maximum frequency word"
}
]
},
{
"form": "application",
"id": "2",
"inip": "4",
"endp": "14",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "NC-S-N6",
"lemma": "application",
"original_form": "application",
"tag_info": "noun, common, singular, medium-high frequency word",
"sense_id_list": [
{
"sense_id": "12fbb0dfc7"
}
]
}
],
"sense_list": [
{
"id": "12fbb0dfc7",
"form": "application",
"info": "sementity/class=class@fiction=nonfiction@id=ODENTITY_PRODUCT@type=Top>Product\tsemld_list=sumo:Artifact\tsemtheme_list/id=ODTHEME_COMPUTING@type=Top>Technology>Computing"
}
],
"sentiment": {
"inherited_sentiment": {
"relation_list": [
{
"id": "23",
"type": "hasInheritedSentiment"
}
],
"score_tag": "P"
}
},
"topic_list": {
"concept_list": [
{
"form": "application",
"id": "12fbb0dfc7",
"dictionary": "-",
"sementity": {
"class": "class",
"fiction": "nonfiction",
"id": "ODENTITY_PRODUCT",
"type": "Top>Product"
},
"semld_list": [
"sumo:Artifact"
],
"semtheme_list": [
{
"id": "ODTHEME_COMPUTING",
"type": "Top>Technology>Computing"
}
]
}
]
}
}
]
},
{
"type": "multiword",
"form": "has earned",
"id": "14",
"inip": "16",
"endp": "25",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"head": "3",
"syntactic_tree_relation_list": [
{
"id": "19",
"type": "iof_isSubject"
},
{
"id": "20",
"type": "iof_isDirectObject"
}
],
"analysis_list": [
{
"origin": "SEG",
"tag": "VI-S3PPA-N-N9",
"lemma": "earn",
"original_form": "has earned",
"tag_info": "verb, indicative, singular, 3rd person, present, perfect, active, maximum frequency word"
}
],
"sentiment": {
"self_sentiment": {
"text": "earn",
"inip": "16",
"endp": "25",
"tag_stack": "P",
"confidence": "100",
"score_tag": "P"
}
}
},
{
"type": "phrase",
"form": "rave reviews from many major tech sites",
"id": "20",
"inip": "27",
"endp": "65",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"head": "6",
"syntactic_tree_relation_list": [
{
"id": "14",
"type": "isDirectObject"
}
],
"analysis_list": [
{
"origin": "SEG",
"tag": "GN-P3D--",
"lemma": "review",
"original_form": "rave reviews",
"tag_info": "phrase, nominal, plural, 3rd person, direct object"
}
],
"token_list": [
{
"form": "rave",
"id": "5",
"inip": "27",
"endp": "30",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "NC-S-N-",
"lemma": "rave",
"original_form": "rave",
"tag_info": "noun, common, singular"
}
]
},
{
"form": "reviews",
"id": "6",
"inip": "32",
"endp": "38",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "NC-P-N5",
"lemma": "review",
"original_form": "reviews",
"tag_info": "noun, common, plural, medium frequency word",
"sense_id_list": [
{
"sense_id": "d01b3dc623"
}
]
}
],
"sense_list": [
{
"id": "d01b3dc623",
"form": "exam",
"info": "sementity/class=class@fiction=nonfiction@id=ODENTITY_EVENT@type=Top>Event\tsemld_list=sumo:Meeting"
}
],
"sentiment": {
"inherited_sentiment": {
"relation_list": [
{
"id": "23",
"type": "hasInheritedSentiment"
}
],
"score_tag": "P"
}
}
},
{
"type": "phrase",
"form": "from many major tech sites",
"id": "22",
"inip": "40",
"endp": "65",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"head": "7",
"analysis_list": [
{
"origin": "SEG",
"tag": "GY------",
"lemma": "from",
"original_form": "from many major tech sites",
"tag_info": "phrase, prepositional"
}
],
"token_list": [
{
"form": "from",
"id": "7",
"inip": "40",
"endp": "43",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "YN8",
"lemma": "from",
"original_form": "from",
"tag_info": "preposition, very high frequency word"
}
]
},
{
"type": "phrase",
"form": "many major tech sites",
"id": "21",
"inip": "45",
"endp": "65",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"head": "11",
"analysis_list": [
{
"origin": "SEG",
"tag": "GN-P3---",
"lemma": "site",
"original_form": "many major tech sites",
"tag_info": "phrase, nominal, plural, 3rd person"
}
],
"token_list": [
{
"form": "many",
"id": "8",
"inip": "45",
"endp": "48",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "QD-PPN7",
"lemma": "many",
"original_form": "many",
"tag_info": "quantifier, determiner, plural, positive, high frequency word"
}
]
},
{
"form": "major",
"id": "9",
"inip": "50",
"endp": "54",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "NC-S-N6",
"lemma": "major",
"original_form": "major",
"tag_info": "noun, common, singular, medium-high frequency word",
"sense_id_list": [
{
"sense_id": "8252e8f651"
}
]
}
],
"sense_list": [
{
"id": "8252e8f651",
"form": "captain",
"info": "sementity/class=class@fiction=nonfiction@id=ODENTITY_TITLE@type=Top>OtherEntity>Title\tsemld_list=sumo:Title\tsemtheme_list/id=ODTHEME_MILITARY@type=Top>Society>Militar"
}
]
},
{
"form": "tech",
"id": "10",
"inip": "56",
"endp": "59",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "NC-S-N-",
"lemma": "tech",
"original_form": "tech",
"tag_info": "noun, common, singular"
}
]
},
{
"form": "sites",
"id": "11",
"inip": "61",
"endp": "65",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "1",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "NC-P-N6",
"lemma": "site",
"original_form": "sites",
"tag_info": "noun, common, plural, medium-high frequency word"
}
]
}
]
}
]
}
]
}
]
},
{
"form": ".",
"id": "12",
"inip": "66",
"endp": "66",
"style": {
"isBold": "no",
"isItalics": "no",
"isUnderlined": "no",
"isTitle": "no"
},
"separation": "A",
"quote_level": "0",
"affected_by_negation": "no",
"analysis_list": [
{
"origin": "SEG",
"tag": "1D--",
"lemma": ".",
"original_form": ".",
"tag_info": "punctuation, other"
}
]
}
]
}
],
"global_sentiment": {
"model": "general_en",
"score_tag": "P",
"agreement": "AGREEMENT",
"subjectivity": "OBJECTIVE",
"confidence": "100",
"irony": "NONIRONIC"
}
}
The application has earned rave reviews from many major tech sites.
<?xml version="1.0" encoding="utf-8"?>
<response>
<status code="0" credits="1">
<![CDATA[OK]]>
</status>
<token_list>
<token>
<type>sentence</type>
<id>15</id>
<inip>0</inip>
<endp>66</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>A</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<sentiment>
<self_sentiment>
<text>
<![CDATA[*]]>
</text>
<inip>0</inip>
<endp>66</endp>
<tag_stack>P</tag_stack>
<confidence>100</confidence>
<score_tag>P</score_tag>
</self_sentiment>
</sentiment>
<token_list>
<token>
<type>phrase</type>
<form>
<![CDATA[The application has earned rave reviews from many major tech sites]]>
</form>
<id>23</id>
<inip>0</inip>
<endp>65</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>_</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>Z-----------</tag>
<lemma>
<![CDATA[*]]>
</lemma>
<original_form>
<![CDATA[The application has earned rave reviews from many major tech sites]]>
</original_form>
<tag_info>clause</tag_info>
</analysis>
</analysis_list>
<sentiment>
<self_sentiment>
<text>
<![CDATA[The application has earned rave reviews from many major tech sites]]>
</text>
<inip>0</inip>
<endp>65</endp>
<tag_stack>P</tag_stack>
<confidence>100</confidence>
<score_tag>P</score_tag>
</self_sentiment>
</sentiment>
<topic_list>
<relation_list>
<relation>
<form>
<![CDATA[The application has earned rave reviews from many major tech sites.]]>
</form>
<inip>0</inip>
<endp>65</endp>
<subject>
<form>
<![CDATA[The application]]>
</form>
<lemma_list>
<lemma>
<![CDATA[application]]>
</lemma>
</lemma_list>
<sense_id_list>
<sense_id>
<![CDATA[12fbb0dfc7]]>
</sense_id>
</sense_id_list>
</subject>
<verb>
<form>
<![CDATA[has earned]]>
</form>
<lemma_list>
<lemma>
<![CDATA[earn]]>
</lemma>
</lemma_list>
</verb>
<complement_list>
<complement>
<form>
<![CDATA[rave reviews from many major tech sites]]>
</form>
<type>isDirectObject</type>
</complement>
</complement_list>
<degree>1</degree>
</relation>
</relation_list>
</topic_list>
<token_list>
<token>
<type>phrase</type>
<form>
<![CDATA[The application]]>
</form>
<id>19</id>
<inip>0</inip>
<endp>14</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>_</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<head>2</head>
<syntactic_tree_relation_list>
<syntactic_tree_relation>
<id>14</id>
<type>isSubject</type>
</syntactic_tree_relation>
</syntactic_tree_relation_list>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>GN-S3S--</tag>
<lemma>
<![CDATA[application]]>
</lemma>
<original_form>
<![CDATA[The application]]>
</original_form>
<tag_info>phrase, nominal, singular, 3rd person, subject</tag_info>
</analysis>
</analysis_list>
<token_list>
<token>
<form>
<![CDATA[The]]>
</form>
<id>1</id>
<inip>0</inip>
<endp>2</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>_</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>TD-SN9</tag>
<lemma>
<![CDATA[the]]>
</lemma>
<original_form>
<![CDATA[the]]>
</original_form>
<tag_info>article, determiner, singular, maximum frequency word</tag_info>
</analysis>
</analysis_list>
</token>
<token>
<form>
<![CDATA[application]]>
</form>
<id>2</id>
<inip>4</inip>
<endp>14</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>NC-S-N6</tag>
<lemma>
<![CDATA[application]]>
</lemma>
<original_form>
<![CDATA[application]]>
</original_form>
<tag_info>noun, common, singular, medium-high frequency word</tag_info>
<sense_id_list>
<sense_id>
<![CDATA[12fbb0dfc7]]>
</sense_id>
</sense_id_list>
</analysis>
</analysis_list>
<sense_list>
<sense>
<id>
<![CDATA[12fbb0dfc7]]>
</id>
<form>application</form>
<info>
<![CDATA[sementity/class=class@fiction=nonfiction@id=ODENTITY_PRODUCT@type=Top>Product semld_list=sumo:Artifact semtheme_list/id=ODTHEME_COMPUTING@type=Top>Technology>Computing]]>
</info>
</sense>
</sense_list>
<sentiment>
<inherited_sentiment>
<relation_list>
<relation>
<id>23</id>
<type>hasInheritedSentiment</type>
</relation>
</relation_list>
<score_tag>P</score_tag>
<score_tag>P</score_tag>
</inherited_sentiment>
</sentiment>
<topic_list>
<concept_list>
<concept>
<form>
<![CDATA[application]]>
</form>
<id>12fbb0dfc7</id>
<dictionary>-</dictionary>
<sementity>
<class>
<![CDATA[class]]>
</class>
<fiction>
<![CDATA[nonfiction]]>
</fiction>
<id>
<![CDATA[ODENTITY_PRODUCT]]>
</id>
<type>
<![CDATA[Top>Product]]>
</type>
</sementity>
<semld_list>
<semld>
<![CDATA[sumo:Artifact]]>
</semld>
</semld_list>
<semtheme_list>
<semtheme>
<id>
<![CDATA[ODTHEME_COMPUTING]]>
</id>
<type>
<![CDATA[Top>Technology>Computing]]>
</type>
</semtheme>
</semtheme_list>
</concept>
</concept_list>
</topic_list>
</token>
</token_list>
</token>
<token>
<type>multiword</type>
<form>
<![CDATA[has earned]]>
</form>
<id>14</id>
<inip>16</inip>
<endp>25</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<head>3</head>
<syntactic_tree_relation_list>
<syntactic_tree_relation>
<id>19</id>
<type>iof_isSubject</type>
</syntactic_tree_relation>
<syntactic_tree_relation>
<id>20</id>
<type>iof_isDirectObject</type>
</syntactic_tree_relation>
</syntactic_tree_relation_list>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>VI-S3PPA-N-N9</tag>
<lemma>
<![CDATA[earn]]>
</lemma>
<original_form>
<![CDATA[has earned]]>
</original_form>
<tag_info>verb, indicative, singular, 3rd person, present, perfect, active, maximum frequency word</tag_info>
</analysis>
</analysis_list>
<sentiment>
<self_sentiment>
<text>
<![CDATA[earn]]>
</text>
<inip>16</inip>
<endp>25</endp>
<tag_stack>P</tag_stack>
<confidence>100</confidence>
<score_tag>P</score_tag>
</self_sentiment>
</sentiment>
</token>
<token>
<type>phrase</type>
<form>
<![CDATA[rave reviews from many major tech sites]]>
</form>
<id>20</id>
<inip>27</inip>
<endp>65</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<head>6</head>
<syntactic_tree_relation_list>
<syntactic_tree_relation>
<id>14</id>
<type>isDirectObject</type>
</syntactic_tree_relation>
</syntactic_tree_relation_list>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>GN-P3D--</tag>
<lemma>
<![CDATA[review]]>
</lemma>
<original_form>
<![CDATA[rave reviews]]>
</original_form>
<tag_info>phrase, nominal, plural, 3rd person, direct object</tag_info>
</analysis>
</analysis_list>
<token_list>
<token>
<form>
<![CDATA[rave]]>
</form>
<id>5</id>
<inip>27</inip>
<endp>30</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>NC-S-N-</tag>
<lemma>
<![CDATA[rave]]>
</lemma>
<original_form>
<![CDATA[rave]]>
</original_form>
<tag_info>noun, common, singular</tag_info>
</analysis>
</analysis_list>
</token>
<token>
<form>
<![CDATA[reviews]]>
</form>
<id>6</id>
<inip>32</inip>
<endp>38</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>NC-P-N5</tag>
<lemma>
<![CDATA[review]]>
</lemma>
<original_form>
<![CDATA[reviews]]>
</original_form>
<tag_info>noun, common, plural, medium frequency word</tag_info>
<sense_id_list>
<sense_id>
<![CDATA[d01b3dc623]]>
</sense_id>
</sense_id_list>
</analysis>
</analysis_list>
<sense_list>
<sense>
<id>
<![CDATA[d01b3dc623]]>
</id>
<form>exam</form>
<info>
<![CDATA[sementity/class=class@fiction=nonfiction@id=ODENTITY_EVENT@type=Top>Event semld_list=sumo:Meeting]]>
</info>
</sense>
</sense_list>
<sentiment>
<inherited_sentiment>
<relation_list>
<relation>
<id>23</id>
<type>hasInheritedSentiment</type>
</relation>
</relation_list>
<score_tag>P</score_tag>
<score_tag>P</score_tag>
</inherited_sentiment>
</sentiment>
</token>
<token>
<type>phrase</type>
<form>
<![CDATA[from many major tech sites]]>
</form>
<id>22</id>
<inip>40</inip>
<endp>65</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<head>7</head>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>GY------</tag>
<lemma>
<![CDATA[from]]>
</lemma>
<original_form>
<![CDATA[from many major tech sites]]>
</original_form>
<tag_info>phrase, prepositional</tag_info>
</analysis>
</analysis_list>
<token_list>
<token>
<form>
<![CDATA[from]]>
</form>
<id>7</id>
<inip>40</inip>
<endp>43</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>YN8</tag>
<lemma>
<![CDATA[from]]>
</lemma>
<original_form>
<![CDATA[from]]>
</original_form>
<tag_info>preposition, very high frequency word</tag_info>
</analysis>
</analysis_list>
</token>
<token>
<type>phrase</type>
<form>
<![CDATA[many major tech sites]]>
</form>
<id>21</id>
<inip>45</inip>
<endp>65</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<head>11</head>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>GN-P3---</tag>
<lemma>
<![CDATA[site]]>
</lemma>
<original_form>
<![CDATA[many major tech sites]]>
</original_form>
<tag_info>phrase, nominal, plural, 3rd person</tag_info>
</analysis>
</analysis_list>
<token_list>
<token>
<form>
<![CDATA[many]]>
</form>
<id>8</id>
<inip>45</inip>
<endp>48</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>QD-PPN7</tag>
<lemma>
<![CDATA[many]]>
</lemma>
<original_form>
<![CDATA[many]]>
</original_form>
<tag_info>quantifier, determiner, plural, positive, high frequency word</tag_info>
</analysis>
</analysis_list>
</token>
<token>
<form>
<![CDATA[major]]>
</form>
<id>9</id>
<inip>50</inip>
<endp>54</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>NC-S-N6</tag>
<lemma>
<![CDATA[major]]>
</lemma>
<original_form>
<![CDATA[major]]>
</original_form>
<tag_info>noun, common, singular, medium-high frequency word</tag_info>
<sense_id_list>
<sense_id>
<![CDATA[8252e8f651]]>
</sense_id>
</sense_id_list>
</analysis>
</analysis_list>
<sense_list>
<sense>
<id>
<![CDATA[8252e8f651]]>
</id>
<form>captain</form>
<info>
<![CDATA[sementity/class=class@fiction=nonfiction@id=ODENTITY_TITLE@type=Top>OtherEntity>Title semld_list=sumo:Title semtheme_list/id=ODTHEME_MILITARY@type=Top>Society>Militar]]>
</info>
</sense>
</sense_list>
</token>
<token>
<form>
<![CDATA[tech]]>
</form>
<id>10</id>
<inip>56</inip>
<endp>59</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>NC-S-N-</tag>
<lemma>
<![CDATA[tech]]>
</lemma>
<original_form>
<![CDATA[tech]]>
</original_form>
<tag_info>noun, common, singular</tag_info>
</analysis>
</analysis_list>
</token>
<token>
<form>
<![CDATA[sites]]>
</form>
<id>11</id>
<inip>61</inip>
<endp>65</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>1</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>NC-P-N6</tag>
<lemma>
<![CDATA[site]]>
</lemma>
<original_form>
<![CDATA[sites]]>
</original_form>
<tag_info>noun, common, plural, medium-high frequency word</tag_info>
</analysis>
</analysis_list>
</token>
</token_list>
</token>
</token_list>
</token>
</token_list>
</token>
</token_list>
</token>
<token>
<form>
<![CDATA[.]]>
</form>
<id>12</id>
<inip>66</inip>
<endp>66</endp>
<style>
<isBold>no</isBold>
<isItalics>no</isItalics>
<isUnderlined>no</isUnderlined>
<isTitle>no</isTitle>
</style>
<separation>A</separation>
<quote_level>0</quote_level>
<affected_by_negation>no</affected_by_negation>
<analysis_list>
<analysis>
<origin>SEG</origin>
<tag>1D--</tag>
<lemma>
<![CDATA[.]]>
</lemma>
<original_form>
<![CDATA[.]]>
</original_form>
<tag_info>punctuation, other</tag_info>
</analysis>
</analysis_list>
</token>
</token_list>
</token>
</token_list>
<global_sentiment>
<model>general_en</model>
<score_tag>P</score_tag>
<agreement>AGREEMENT</agreement>
<subjectivity>OBJECTIVE</subjectivity>
<confidence>100</confidence>
<irony>NONIRONIC</irony>
</global_sentiment>
</response>
If of=img the response will be a gif image with the syntactic tree. When we select a sentiment model in the call to the API (for instance, sm=general the tree will show the sentiment information.
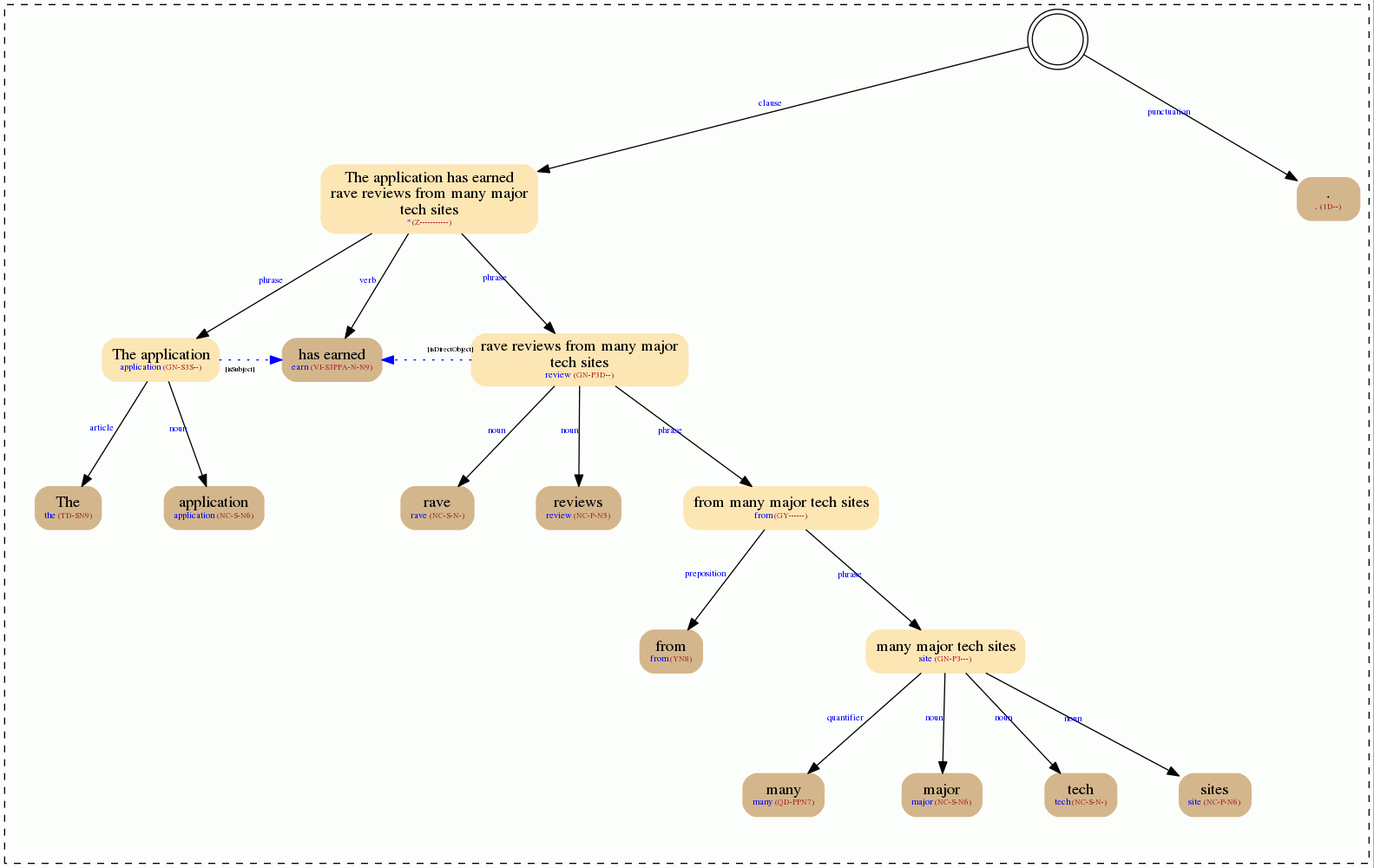
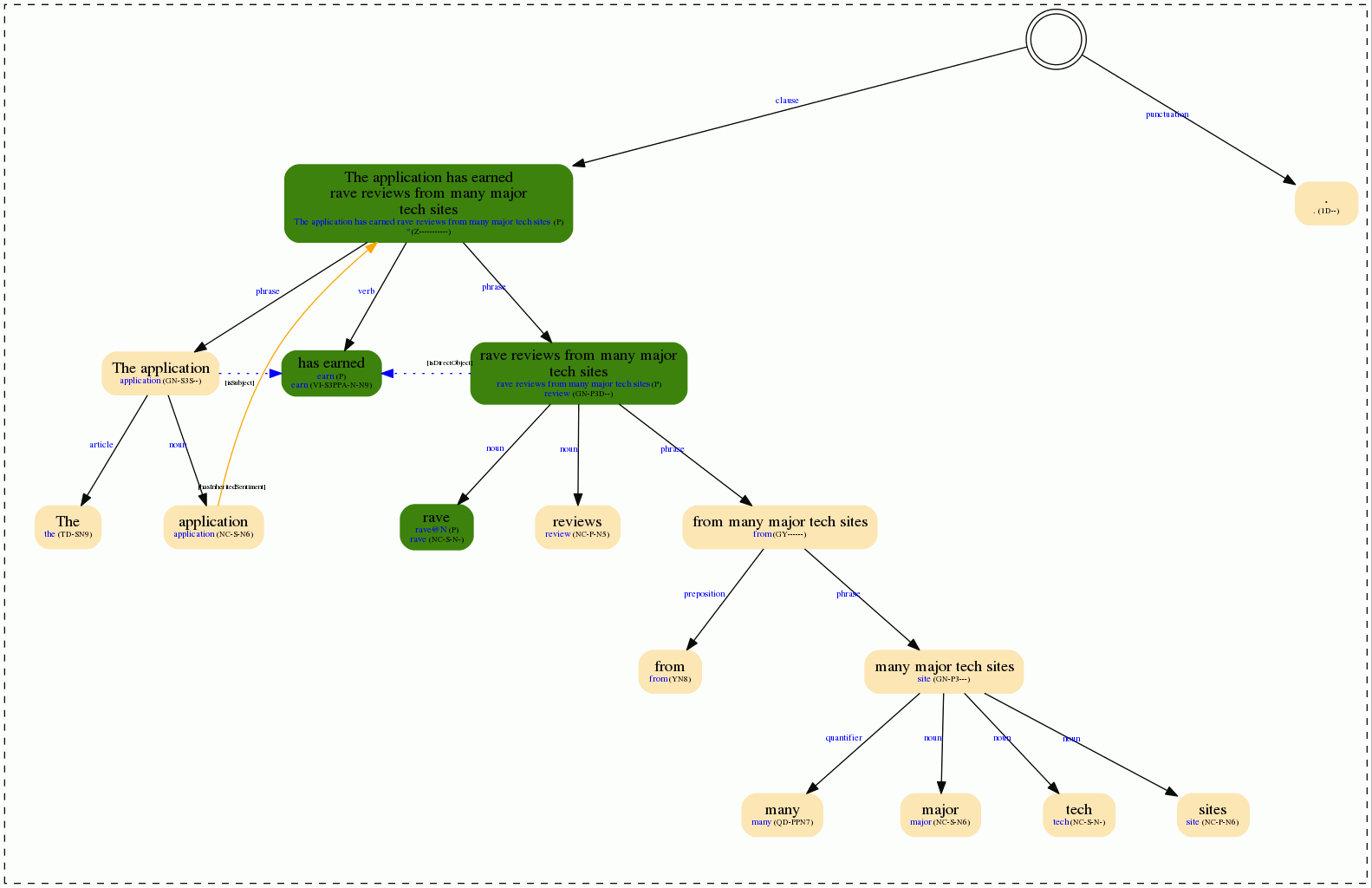
The field self_sentiment is shown through nodes of different colors, while the inherited_sentiment will appear as yellow arrows between nodes:
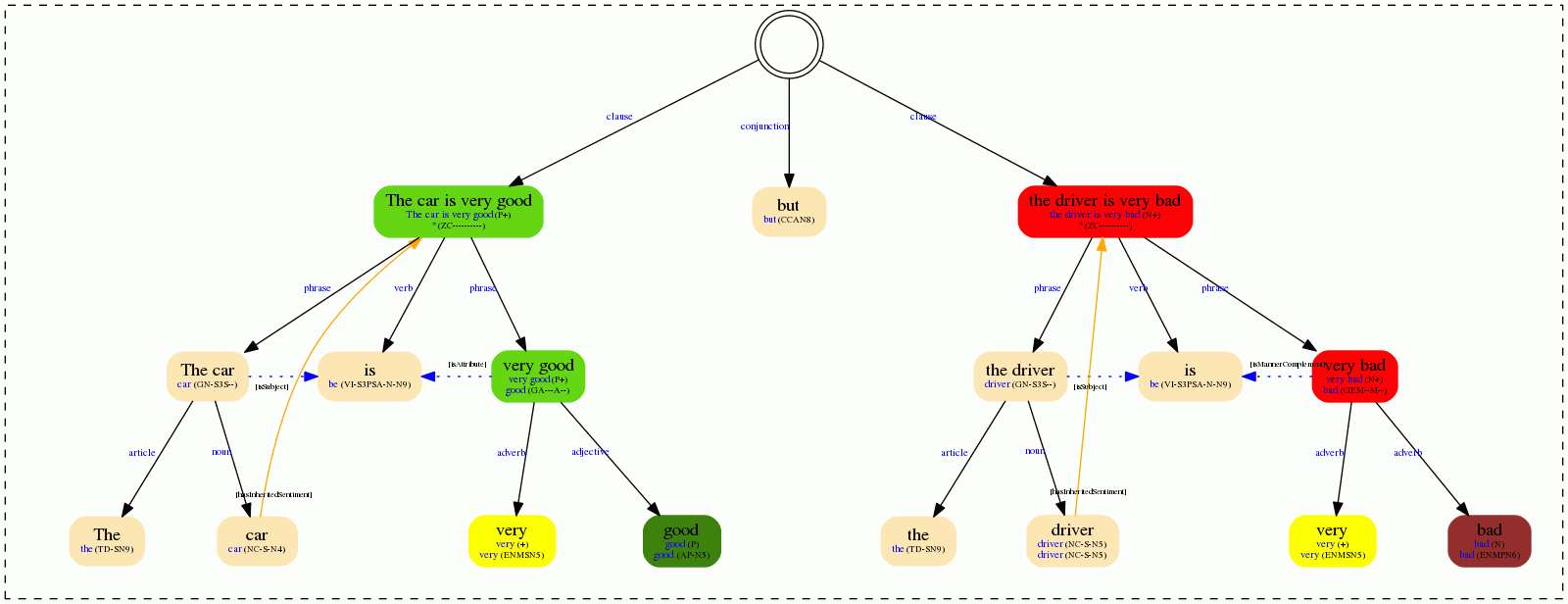
The brighter the node, the stronger the polarity, and modifiers and negators are represented in yellow.
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2025 © All Rights Reserved | Data protection policy | Terms and conditions MeaningCloud is a a trademark by MeaningCloud LLC