
MeaningCloud Operators
As we have mentioned, in this extension the different APIs of MeaningCloud will be available as operators you will be able to include in your own processes.
The six operators included provide functionality from five different MeaningCloud APIs. Follow the links below to see in detail the parameters each one of them needs:
- Topics Extraction
- Text Classification
- Sentiment Analysis
- Aspect-based Sentiment Analysis
- Lemmatizer
- Deep Categorization
You will also be able to combine them in the same process to run different types of anlyses over the same input data:
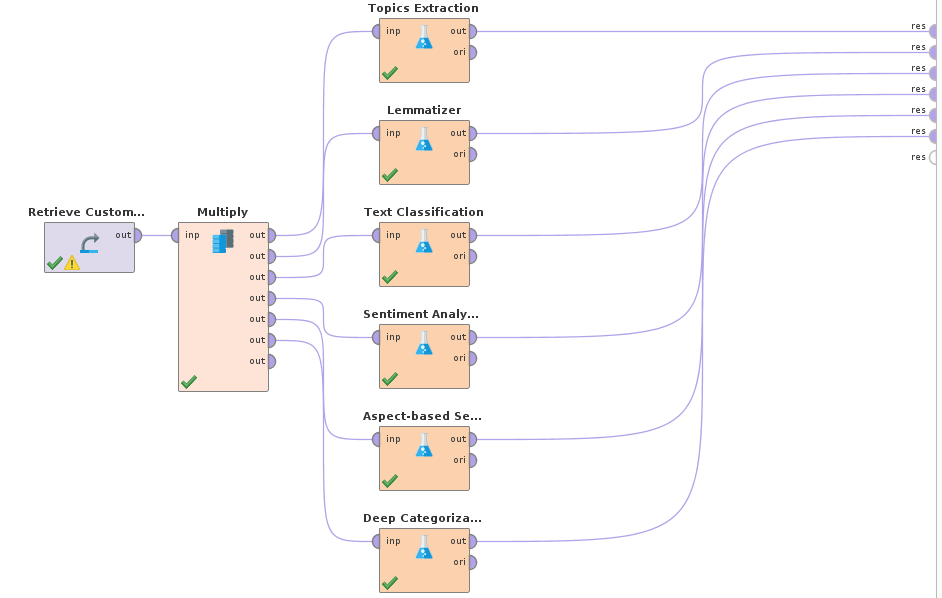
Data input
There is one parameter that's common to all of MeaningCloud's operators: the text you are going to analyze. This text will be input in the Attribute parameter using the name of the column from the data source where the text is located.

Other parameters
The rest of the parameters available for each operator are more related to the specific functionality the provide. Check the sections below to learn more about each one of them.
Topics Extraction
Description: Topics Extraction is MeaningCloud's solution for extracting the different elements present in sources of information. This detection process is carried out by combining a number of complex natural language processing techniques that allow to obtain morphological, syntactic and semantic analyses of a text and use them to identify different types of significant elements. This operator will allow you to extract entities and concepts.
API Version: Topics Extraction 2.0.
Required parameters: "Text language" (lang) and "Output language" (ilang).
Other parameters: "Unknown words" (uw), "Relaxed typography" (rt), user dictionaries (ud), extract entities (tt=e) and extract concepts (tt=c). By clicking on "Show advanced parameters", you will be able to filter which ontology types you want to extract, both for entities and concepts. By default, texts are sent using txtf=markup, so texts with HTML can be processed.
Output: in the output you will obtain a sparse matrix where each concept and/or entity found in the text will be a new attribute of the documents with a 0 or a 1 to indicate if it was detected on the text (or their relevance by the number of times detected if the Keep weights parameter is enabled). Entities will start with the prefix "ent_" while concepts will start by "con_".
Did you notice...?
If there are several concepts or entities with the same form, the weights obtained in the response are the sum of the weights of all of them.
Text Classification
Description: Text Classification is MeaningCloud's solution for automatic text classification according to pre-established categories defined in a model. The algorithm used combines statistic classification with rule-based filtering, which allows to obtain a high degree of precision for very different environments.
API Version: Text Classification 2.0.
Required parameters: "Model" (model).
Other parameters: keep weights, which lets you select if you want the relevance assigned to an entity or a concept in the output, or if you want just to know if it has been detected in the text.
Output: in the output you will obtain a sparse matrix where each category found for the texts will be a new attribute of the documents with a 0 or a 1 to indicate if the text was classified in it, or the relevance, when the Keep weights parameter is enabled. Categories will be named using the category code.
Important
If you select an operator and you don't have your license key configured, the models won't appear until you configure the key and reload the operator.
Sentiment Analysis
Description: Sentiment Analysis is MeaningCloud's solution for performing a detailed multilingual sentiment analysis of texts from different sources. The text provided is analyzed to determine if it expresses a positive/negative/neutral sentiment; to do this, the local polarity of the different sentences in the text is identified and the relationship between them evaluated, resulting in a global polarity value for the whole text.
API Version: Sentiment Analysis 2.1.
Required parameters: "Text language" (lang).
Other parameters: "Sentiment model" (model), "User dictionaries" (ud), "Unknown words" (uw) and "Relaxed typography" (rt). By default, texts are sent using txtf=markup, so texts with HTML can be processed and model=general if none is specified.
Output: in the output you will obtain five new attributes with information related to the global sentiment of the text processed: polarity, confidence, agreement, subjectivity and irony.
Lemmatizer
Description: Lemmatization, PoS and Parsing is the name of MeaningCloud's API for the different basic linguistic modules. Even though it is simple in name, the parser contains a myriad of functionalities derived from the complete morphosyntactic and semantic analysis it carries out. In this operator, only the lemmatization functionality is implemented.
API Version: Lemmatization, POS and Parsing 2.0.
Required parameters: "Text language" (lang).
Other parameters: "Unknown words" (uw), "Relaxed typography" (rt), "User dictionaries" (ud), "Keep stopwords" (when disabled, only nouns, verbs, adjectives and adverbs are output) and "Keep weights" (to count the appearances of the same lemma in a text). By default, texts are sent using txtf=markup, so texts with HTML can be processed.
Output: in the output you will obtain a sparse matrix where each lemma found in the text will be a new attribute named following the pattern "lem_[lemma]". The matrix will contain zeros or ones if "Keep weights" is disabled to mark if the lemma appears in the text, or the number of times it appears if "Keep weights" is enabled.
Aspect-based Sentiment Analysis
Description: Besides polarity at sentence and global level, Sentiment Analysis uses advanced natural language processing techniques to also detect the polarity associated to both entities and concepts in the text.
API Version: Sentiment Analysis 2.1.
Required parameters: "Text language" (lang).
Other parameters: "Sentiment Model" (model), "User dictionaries" (ud), "Unknown words" (uw) and "Relaxed typography" (rt). Also, you can choose the type of aspects you want to obtain (concepts and/or entities) with the "Extract entities" and "Extract models" parameters. By default, texts are sent using txtf=markup, so texts with HTML can be processed and model=general if none is specified.
Output: in the output, you will obtain an extra column with a list of the polarities of every concept and entity with the following scheme: [entity/concept]:[polarity] separated by pipes ("|").
Deep Categorization
Description: Deep Categorization is MeaningCloud's solution for in-depth rule-based categorization. It assigns one or more categories to a text, using a very detailed rule-based language that allows you to identify very specific scenarios and patterns using a combination of morphological, semantic and text rules.
API Version: Deep Categorization 1.0.
Required parameters: "Model" (model).
Other parameters: "User dictionaries" (ud) "Keep weights" (to count the appearances of the same lemma in a text). By default, texts are sent using txtf=markup, so texts with HTML can be processed.
Output: in the output you will obtain a sparse matrix where each category found for the texts will be a new attribute of the documents with a 0 or a 1 to indicate if the text was categorized in it, or the relevance, when the Keep weights parameter is enabled.
Important
Many of the models available for this API are included in vertical packs, so do make sure to request access for them to appear in the drop down menu.
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2025 © All Rights Reserved | Data protection policy | Terms and conditions MeaningCloud is a a trademark by MeaningCloud LLC