If you love politics, regardless of your party or political orientation, you may know that election periods are exciting moments and having good information is a must to increase the fun. This is why you follow the news, watch or listen to political analysis programs on TV or radio, read surveys or compare different points of view from one or the other side.

American politics
Starting with this, we are publishing a series of tutorials where we will show how to use MeaningCloud for extracting interesting political insights to build your own political intel reports. MeaningCloud provides useful capabilities for extracting meaning from multilingual content in a simple and efficient way. Combining API calls with open source libraries in your favorite programming language is so easy and powerful at the same time that will awaken for sure the Political Data Scientist hidden inside of you. Be warned!
Our research objective is to analyze mentions to people, places, or entities in general in the Politics section of different news media. We will try to carry out an analysis that can answer the following questions:
- Which are the most popular names?
- Does their popularity depend on the political orientation of the newspaper?
- Is it correlated somehow to the popularity surveys or voting intentions polls?
- Do these trends change over time?
Before we begin
This is a technical tutorial in which we will develop some coding. However, we will try to guide you through the whole process, so everyone can follow the explanations and understand the purpose of the tutorial.
For the sake of generality and better understanding, we will focus on U.S. Politics in English, but obviously you can easily adapt the same analysis for your own country or (MeaningCloud supported) language.
And last but not least, this tutorial will use PHP as programming language for the code examples. However, any non-rookie programmer should be able to translate the scripts into any language of their choice.









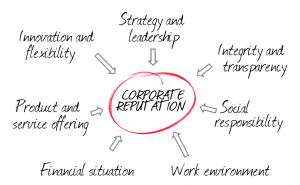 Social monitoring tools provide a basic sentiment analysis that in the best of cases identifies that a certain comment (e.g. a tweet) expresses a positive or negative opinion about an entity, and use the aggregated data in diagrams and temporal evolutions. Nevertheless, analyzing a so multifaceted reality as the reputation of a company requires a more granular opinion analysis.
Social monitoring tools provide a basic sentiment analysis that in the best of cases identifies that a certain comment (e.g. a tweet) expresses a positive or negative opinion about an entity, and use the aggregated data in diagrams and temporal evolutions. Nevertheless, analyzing a so multifaceted reality as the reputation of a company requires a more granular opinion analysis.