In the field of text analytics, aside from the development of categorization models, the application of machine learning (and more specifically, deep learning) has proved to be very helpful for supporting our teams in the process of building/improving rule-based models.
This post analyzes some of the applications of machine/deep learning for NLP tasks, beyond machine/deep learning itself, that are used to approach different scenarios in projects for our customers.
Baseline model for text categorization
In some of our previous posts, we have discussed the pros and cons of traditional natural language processing (NLP) in text analytics versus machine learning approaches (including deep learning).
Machine learning makes model building easy and fast. The drawback is, however, that most often these systems are a black box, where adding new knowledge cannot be done with the exception of adding more samples to the training data and retraining the model. This is specifically applicable for the case of deep learning, as neural networks include millions of parameters and thus are, in practice, very hard or in some cases, impossible to analyze (despite the techniques described in the last section).
On the other hand, traditional NLP methods, including rule-based models (for tasks such as text categorization, sentiment analysis or entity disambiguation), although much more intensive in human work, are still nowadays the best choice for many scenarios in text analytics; as errors are generally easy to correct and precision can be streamlined.
In our solutions, hybrid systems combining machine learning (the machine’s opinion) with rule-based post-filtering (a human-like correction) provide the best results in terms of precision and recall, in many cases.
Villena-Román, Julio; Collada-Pérez, Sonia; Lana-Serrano, Sara; and González-Cristobal, Jose. (2011). Hybrid Approach Combining Machine Learning and a Rule-Based Expert System for Text Categorization. Proceedings of the 24th International Florida Artificial Intelligence Research Society, FLAIRS – 24.
Where a large volume of training data is available, deep learning is usually the best choice (especially, when using modern architectures based on transformers). When training data is scarce, other more classical machine learning techniques, such as decision trees/forest, k-nearest neighbors, or SVMs, can generally provide good results with less computational cost (although with the new “few-shot learning” techniques this may change in the near future).
Then, classical NLP methods are applied over the provided output, involving text normalization and tokenization, Part-of-Speech tagging, parsing, and rule-based models (with rules at all levels of abstraction: lexical, morphosyntactic, and semantic levels), to generate the final output of the system.
This way the global system requires a reduced effort to start, and performance can be improved as much as is necessary by investing time and effort in developing more rules to correct false positives and negatives to increasing both precision and recall.
EXAMPLE APPLICATION. We have developed a categorization model based on the IAB (Interactive Advertising Bureau) taxonomy with over 1200 categories. The hybrid classifier is implemented by first using a tagged corpus for training using deep learning (specifically sequence-to-sequence architecture -transformers- based on DistilBERT), which provides a very good starting point for the most frequent categories in the training corpus (those with several thousands of examples). A rule-based model is then implemented to improve the categorization of the less frequent categories that seldom appear in the corpus (some of them with less than 10 training texts). This approach obviously outperforms the development of both a deep learning classifier (which would need much more texts for training) and also a rule-based model (which would have to contain thousands of rules, costly to develop and difficult to run by the rule engine).
Generation of a starting model
Rule induction techniques are applied to generate a first draft rule model. For this purpose, training texts are provided to the model for each category. Statistical techniques are used to extract frequent n-grams (sequences of N contiguous tokens/words), which include collocations (two or more words that often co-occur and thus, sound natural to native speakers who use them all the time), associated with each category.
 Then rules including these terms are generated for each category, using the appropriate operators, including exact phrases or boolean expressions with AND, OR, NOT operators. Exclusion (“negative”) rules can also be generated by using the most frequent sequences for a given category and comparing them with the most frequent sequences for another category.
Then rules including these terms are generated for each category, using the appropriate operators, including exact phrases or boolean expressions with AND, OR, NOT operators. Exclusion (“negative”) rules can also be generated by using the most frequent sequences for a given category and comparing them with the most frequent sequences for another category.
This first draft model is then reviewed and analyzed by humans, who tend to focus on applying the “human factor” to improve the generated rules and achieve the target performance that is required for each scenario, instead of writing hundreds of rules to account for all categories.
EXAMPLE APPLICATION. We developed a Voice of the Customer model for a telecom company contact center. The customer wanted to have a rule-based model that they could edit. It was a 2-level taxonomy, with 12 categories at the first level and over 900 categories overall. The effort required to develop the model from scratch just by hand would have been overwhelming and probably out of costs. However, the proposed draft model worked quite well for over 75% categories and lowered the required human effort dramatically.
Semantic expansion of rules
Another successful application of machine learning is to improve a given model. Given a set of rules, usually written by humans, semantic expansion techniques are used for improving rule recall, adding extra terms or expressions that are closely related to existing rules but not covered by them.
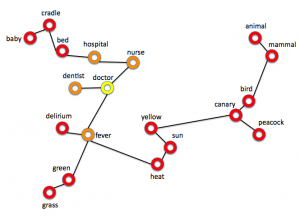 Typically, semantic expansion was performed with traditional techniques based on predefined lexicons of synonyms and antonyms; preferable if suited to the specific domain of the problem. However, nowadays additional terms for rules are suggested using word embeddings models, trained using machine learning. In essence, this means that words in texts are represented in the form of a real-valued vector that encodes their meanings, such that the words that are closer in the vector space are expected to be semantically similar.
Typically, semantic expansion was performed with traditional techniques based on predefined lexicons of synonyms and antonyms; preferable if suited to the specific domain of the problem. However, nowadays additional terms for rules are suggested using word embeddings models, trained using machine learning. In essence, this means that words in texts are represented in the form of a real-valued vector that encodes their meanings, such that the words that are closer in the vector space are expected to be semantically similar.
Although the use of semantic space models started in the 70s with the vector space model for information retrieval by Salton, the milestone was in 2013, when a team at Google created word2vec, a word embedding toolkit that could train vector space models faster and better than the previous approaches, which paved the way for practical application of these techniques.
Mikolov, Tomas; Chen, Kai; Corrado, Greg; and Deanet, Jeffrey. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv:1301.3781.
Since then, more embedding technologies have appeared. Embeddings in word2vec, GloVe, and fastText were context-independent, but currently contextualized embeddings based on BERT (Bidirectional Encoder Representations from Transformers) and derivatives provide better results.
Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; and Toutanova, Kristina. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805v2
In short, given a text corpus, an embedding model can be trained to learn the meaning of words, using word2vec, for instance. Then, for a given word, semantically similar words (synonyms) are found among those which are closer (at a smaller distance) in the semantic space of the vectors in the word embeddings. Instead of having a predefined list of synonyms, related words that are used in similar sentences in the texts are automatically provided by the system.
Rules are expanded by adding semantically related terms to those contained in the rule, thus improving the recall (and in turn, the F-score) of the model.
EXAMPLE APPLICATION. In a recent project for detecting confidential information, using a simple model with a few categories, developed manually based on a reduced size corpus, we applied semantic expansion to increase the performance of the model. In this example, the following synonyms for discrimination were automatically discovered, based solely on the corpus: offense, breach, harassment, racism, racial, minority, segregation, bias, oppression, gender, injustice.
Topic detection for corpus analysis
Clustering and topic detection, using different techniques for textual similarity calculation, can be used in text analytics to support the human analysis of a text corpus and facilitate the development of rules and also find uncovered topics.
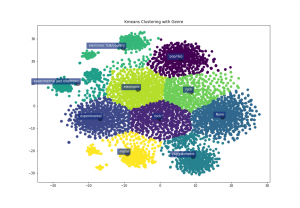 Applying any clustering technique for finding groups of texts avoids having to analyze isolated texts and allows for rules to be written based on the whole groups of texts, simplifying the process of analysis for humans. Any clustering algorithm can be applied, although the most popular algorithm, k-means, is less suitable for this task as the number of clusters (topics in this case) is fixed and must be defined in advance, which is impossible. Thus, other algorithms that allow for a varying number of clusters by providing a distance threshold, such as hierarchical clustering algorithms, are preferred in this case. The definition of the distance metric for the clustering algorithm can be based on word embeddings, as explained in the previous section, which achieves the best results in terms of semantic representation.
Applying any clustering technique for finding groups of texts avoids having to analyze isolated texts and allows for rules to be written based on the whole groups of texts, simplifying the process of analysis for humans. Any clustering algorithm can be applied, although the most popular algorithm, k-means, is less suitable for this task as the number of clusters (topics in this case) is fixed and must be defined in advance, which is impossible. Thus, other algorithms that allow for a varying number of clusters by providing a distance threshold, such as hierarchical clustering algorithms, are preferred in this case. The definition of the distance metric for the clustering algorithm can be based on word embeddings, as explained in the previous section, which achieves the best results in terms of semantic representation.
Topic analysis (also called topic detection, topic modeling, or topic extraction) is an unsupervised machine learning technique that organizes and understands large collections of texts, by assigning “tags” based on the topic or theme of each individual text. There are different algorithms, including SVD (Singular Value Decomposition), the method of moments, NMF (Non-Negative Matrix Factorization), LSA (Latent Semantic Analysis), and LDA (Latent Dirichlet Allocation). Most of them are based on the “distributional hypothesis” principle: words that occur in similar texts have similar meanings.
The modern top2vec algorithm first transforms documents to numeric representations (like a document embedding vector, also allowing the use of BERT embeddings); subsequently, dimensionality reduction is performed using UMAP (Uniform Manifold Approximation and Projection) and then, groups of documents are found using HDBSCAN clustering (Hierarchical Density-Based Spatial Clustering of Applications with Noise). Other new algorithms based on BERT are tBERT and BERTopic.
Angelov, Dimo. (2020). Top2Vec: Distributed Representations of Topics. arXiv:2008.09470
The typical application of these techniques is to identify any topic trend in the given corpus without defining a dictionary of topics/themes to detect. Given a corpus, groups of texts related to one another can be identified using clustering or topic detection. The importance of each group can be estimated with the number of texts contained within it and the degree of similarity among those texts (the more similar the texts are, the higher score for the cluster). In addition, a label (a name/title) can be generated to better identify each group, using frequently repeated strings in the different texts of the group.
EXAMPLE APPLICATION. In a Voice of the Customer project in the banking sector, in addition to developing a categorization model based on the taxonomy that their customer service had been using for years to classify inputs from customers, we applied topic detection to discover specific themes that were mentioned in the texts but were not included in the categorization model. Topics such as debit card for minors and lack of seating in the branch office were found within the texts and addressed appropriately by the customer service.
Explainability techniques for detecting issues in a corpus
Explainability techniques aim to interpret the results of machine learning models, mainly applied to classifiers such as neural networks, which are “opaque” in the sense that it is difficult to understand how they come to a particular decision. These techniques focus on methods that can help explain how classifiers “reason” while performing certain tasks, what they learn, and which information they use for making predictions.
There are some well-known algorithms for explainability, such as SHAP (Shapley Additive Explanations), LIME (Local Interpretable Model-agnostic Explanations), and its variant LIMSSE (Local Interpretable Model-agnostic Substring-based Explanations). ELI5 (Explain Like I’m 5) is a popular toolkit (framework) for explainability in Python. Google LIT (Language Interpretability Tool) is another of the most recent toolkits.
Among all explainability outputs, Salience Maps are the most interesting as they can highlight the most relevant words which cause a given text to be assigned with a given category. Salience Maps can be extracted with “black-box” explainability methods, where the model itself is not inspected and only inputs/outputs are observed, which has obvious advantages being independent of the model.
![]()
For instance, in the example above, the salience map shows that the classifier considers charming and affecting as the most relevant words when assigning a positive sentiment to this text.
The direct use of these methods is to improve the training of a given machine learning classifier. However, this objective can be generalized to extract information about which examples are the most difficult to model, to analyze if the training corpus is consistently tagged, and whether models will behave consistently if wording, textual style, verb tense, or pronoun gender is changed. Google LIT is also used to find patterns in model behavior, such as outlying clusters in embedding space and detect words with outsized importance to the predictions.
This allows us to distinguish important words (where development effort must be invested, for instance, adding more synonyms or related expressions) from less important words (which only provide a minor contribution to the final decision of the classifier).
Conclusions
In this post, some applications of machine/deep learning as a supporting technology in NLP/text analytics for the development of rule-based models have been described. Applications range from providing a baseline model for text categorization, the generation or improvement of rule-based models, helping the tasks of corpus analysis, and explainability methods to detect potential issues with the corpus.
In short, the idea behind all of these aspects is to try and optimize all the involved processes, reducing the human effort required to tackle each project, thus reducing the cost for the customer, while achieving the expected target performance.
