Cada vez son más habituales los escenarios donde se puede extraer un enorme valor del análisis del contenido no estructurado: desde las noticias sobre un sector o empresa hasta el procesamiento de contratos o expedientes médicos. Sin embargo, como sabemos, este contenido no se presta bien a su análisis automático.
La analítica de texto ha venido a cubrir esta necesidad, proporcionando herramientas potentes que nos permiten descubrir temas, menciones, polaridad, etc. en el texto en formato libre. Esto ha hecho posible conseguir un nivel inicial de comprensión y análisis automáticos de los documentos no estructurados, que ha habilitado una generación de aplicaciones semánticas sensibles al contexto en áreas como el análisis de la voz del cliente o la gestión del conocimiento.
No basta con entidades y categorías
Lo que ocurre es que muchas veces no basta con extraer elementos de información aislados del texto. Cuando los documentos son extensos y complejos (por ejemplo, un contrato) no basta con asignarles una categoría general que clasifique el documento en su conjunto o extraer menciones de personas, organizaciones, conceptos, etc. que aparecen en él. Ese enfoque tiene limitaciones a la hora de conseguir encontrar o explotar el documento: es necesario que los insights que extraemos de ellos sean más accionables.
En resumen, cuando el escenario involucra:
- Documentos complejos, con múltiples apartados o segmentos
- Necesidad de extraer datos más profundos y detallados: patrones complejos, relaciones entre elementos…
es necesario un análisis más potente, que denominamos Deep Semantic Analytics.
Deep Semantic Analytics: ¿dónde?
Seguro que algunos de estos escenarios os resultan familiares:
- Pensemos en un proveedor de información comercial sobre compañías. Para entender el “universo de empresas” de un país, la empresa no solo debe analizar millones de estados financieros estructurados, sino también los informes y memorias de gestión (ej.; 10-K en USA) que describen en detalle su actividad y negocio, y extraer de ahí insights profundos tales como las empresas accionistas (con su porcentaje de participación), las empresas participadas, la concentración de la cifra de ventas en determinados clientes, etc. Para ello es necesario aplicar una analítica de texto muy sofisticada.
- En una aplicación de agregación y seguimiento de noticias en contextos de inteligencia de mercado y competitiva, la posibilidad de detectar no solo menciones de ciertas empresas /marcas, sino market-moving information en forma de relaciones complejas tales como noticias sobre fusiones y adquisiciones, grandes proyectos, compraventa de activos, desabastecimiento de materias primas, etc. tiene una utilidad mucho más clara.
- Para un proveedor de servicios de salud (administración pública sanitaria, hospital, empresa farmacéutica), los datos no estructurados contenidos en historiales clínicos electrónicos son una fuente de información de extraordinario valor en lo que tiene que ver con relación entre síntomas, tratamientos seguidos, sus resultados, etc. La posibilidad de extraer esta información de manera automática y masiva de los expedientes y poder hacer minería sobre ella le permitiría entender mejor la prevalencia de las diversas enfermedades y la eficacia de los tratamientos.
- La documentación legal (contratos, acuerdos, casos, sentencias) es el ejemplo paradigmático de contenido no estructurado de alto valor. Bufetes de abogados y departamentos jurídicos de empresas se beneficiarían de herramientas que permitieran extraer datos complejos tales como las partes en un contrato, los términos de una determinada cláusula, los afectados por y la naturaleza de una sentencia, etc. para poder analizarlos, relacionarlos y entenderlos mejor.
Vamos a profundizar en este último caso.
¿Qué se puede hacer en cuestión de minutos con una habitación llena de contratos?
Para un departamento legal o un bufete de abogados un proceso de due diligence puede significar analizar miles de documentos (típicamente contratos y similares) relacionados con una empresa, para hacerse una idea agregada de su situación y detectar cuanto antes posibles riesgos.
Tradicionalmente las organizaciones han realizado las tareas de due dilligence de manera manual, categorizando y clasificando los distintos documentos con recursos humanos más o menos especializados. Este proceso es muy laborioso y lento, y está sujeto a los errores e inconsistencias típicos del análisis humano, que se ven exacerbados por los presionantes plazos de tiempo en los que se tiene que realizar la tarea.
Veamos cómo disponer de una herramienta capaz de realizar Deep Semantic Analytics puede simplificar la labor. Esta herramienta podría recibir una colección de contratos y realizar las siguientes actividades:
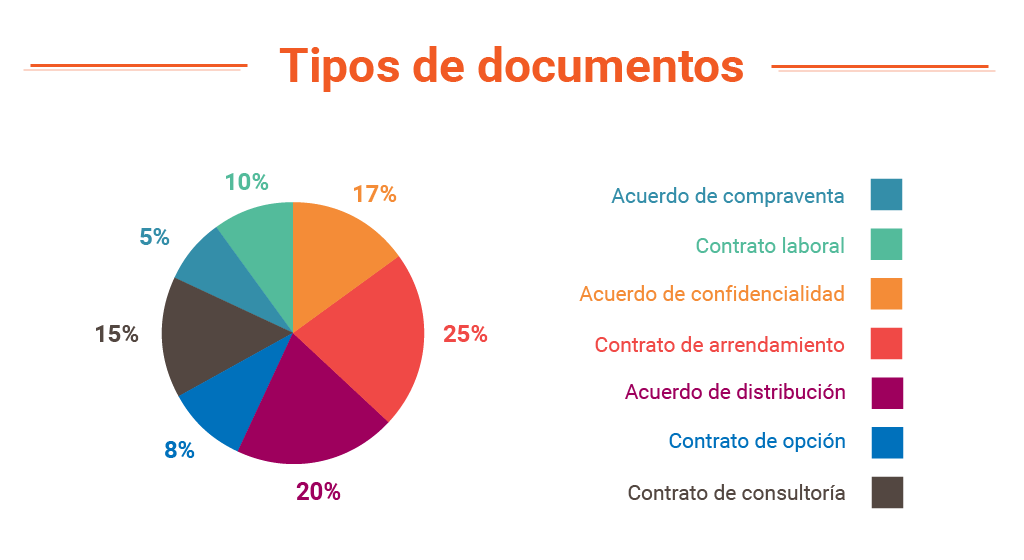
- Clasificar por tipo de documento, por ejemplo, categorizando en grupos como Acuerdo de compraventa, Contrato laboral, Acuerdo de confidencialidad, Contrato de arrendamiento, Contrato de opción, Contrato de consultoría… Se obtiene así un resumen del tipo de documentación que tenemos entre manos
- Analizar cada contrato para detectar e identificar sus cláusulas y otras partes relevantes, por ejemplo, Título, Intervinientes, Fecha, Duración, Cesión, Cambio de control, Auditoría, Derecho aplicable, Fuerza mayor, Indemnización, Limitación de responsabilidad… En esta fase habría que detectar si una cláusula está presente o no, si es similar a otros ejemplos del mismo tipo que se consideran aceptables o si tiene peculiaridades que merezcan un análisis más detallado.
- Dentro de las diferentes cláusulas, extraer los datos y las relaciones que son clave, por ejemplo:
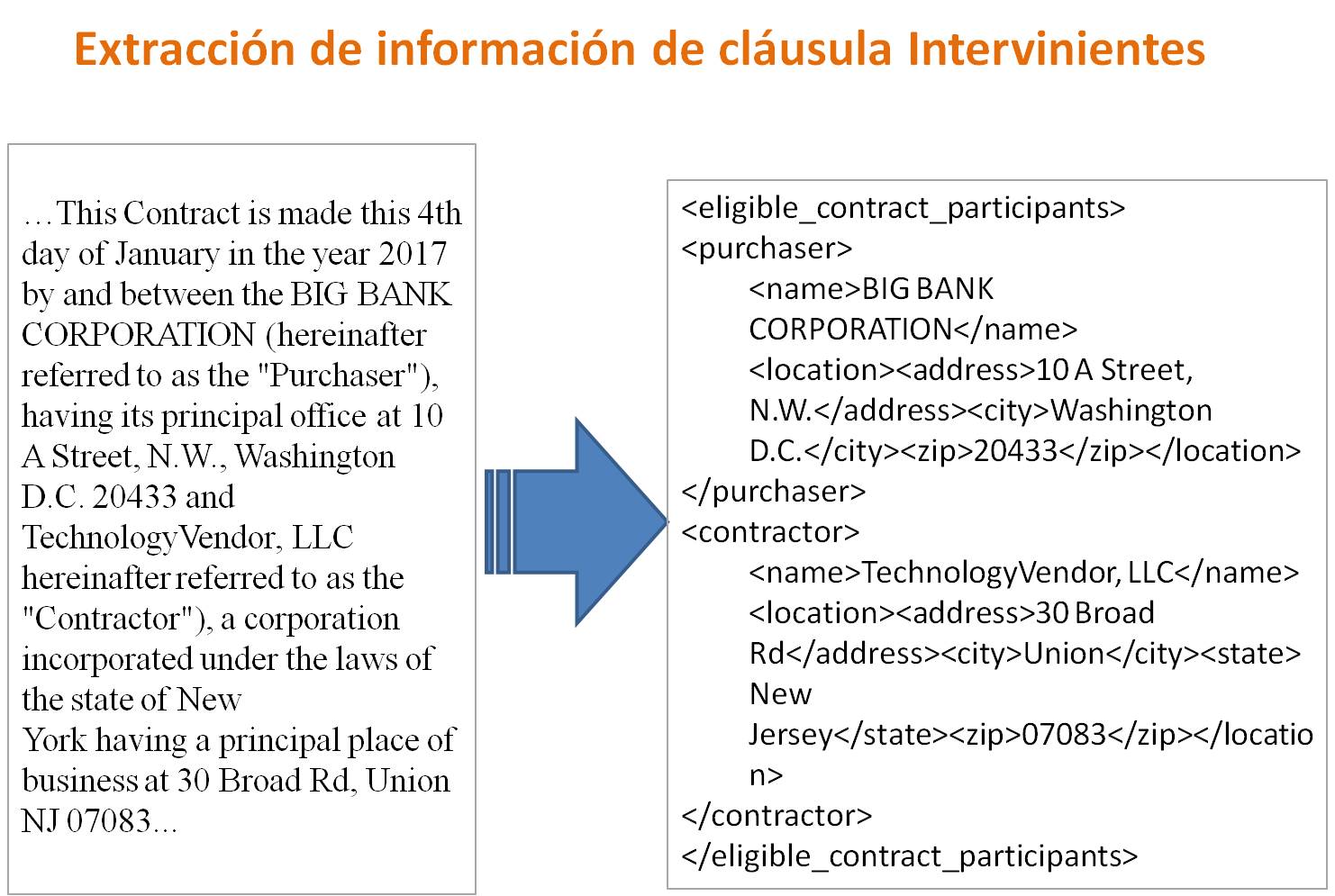
- En Intervinientes, extraer la identificación completa y detallada de las partes.
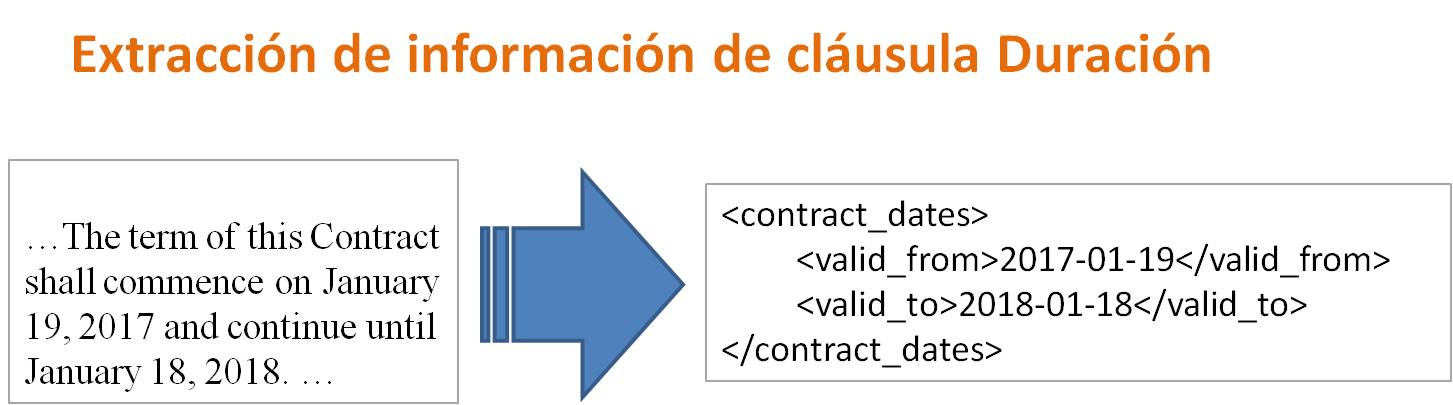
- En Duración, extraer el plazo durante el cual el acuerdo es efectivo.
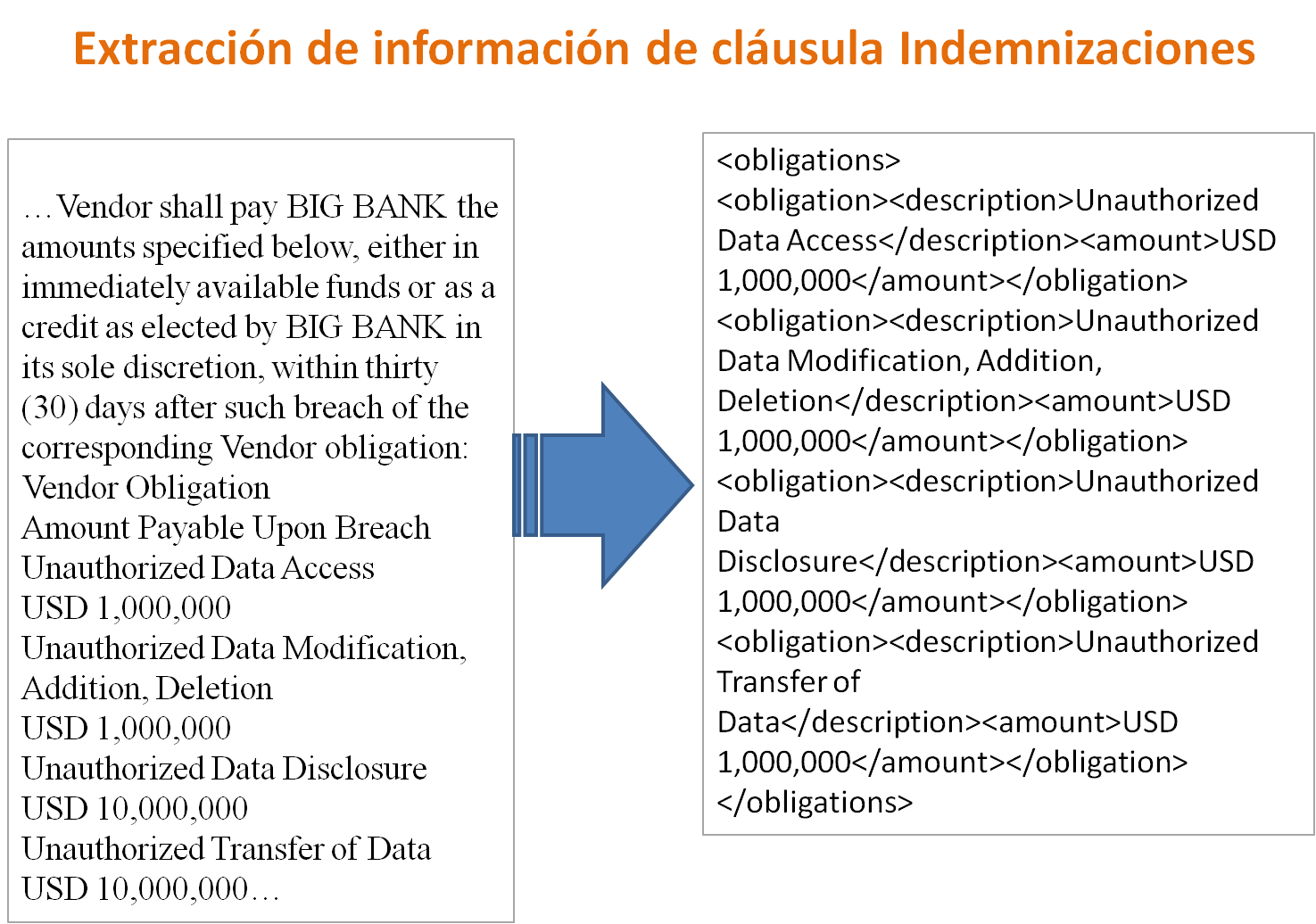
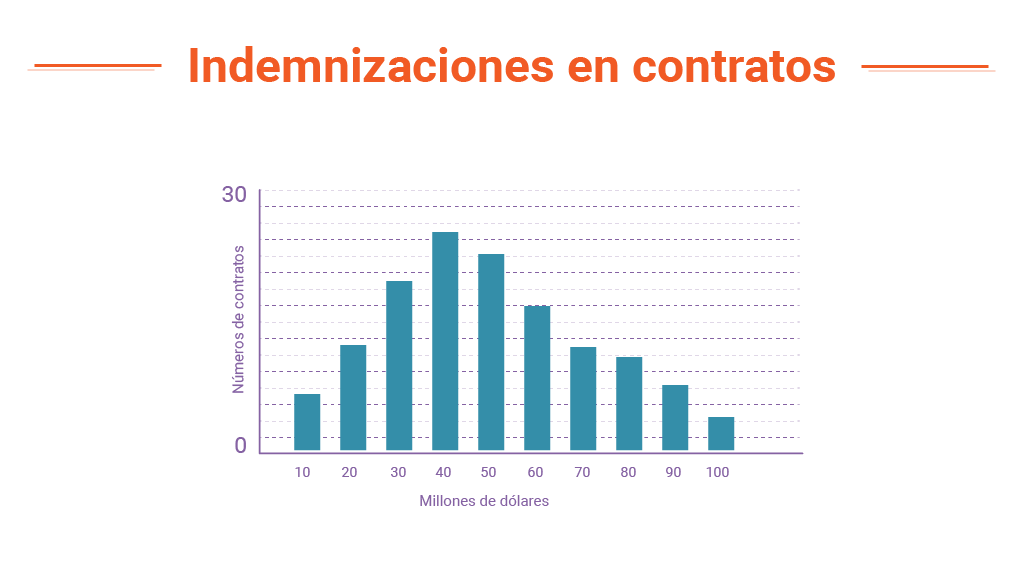
- En Indemnización extraer las circunstancias y las cuantías de la indemnización en cada caso.
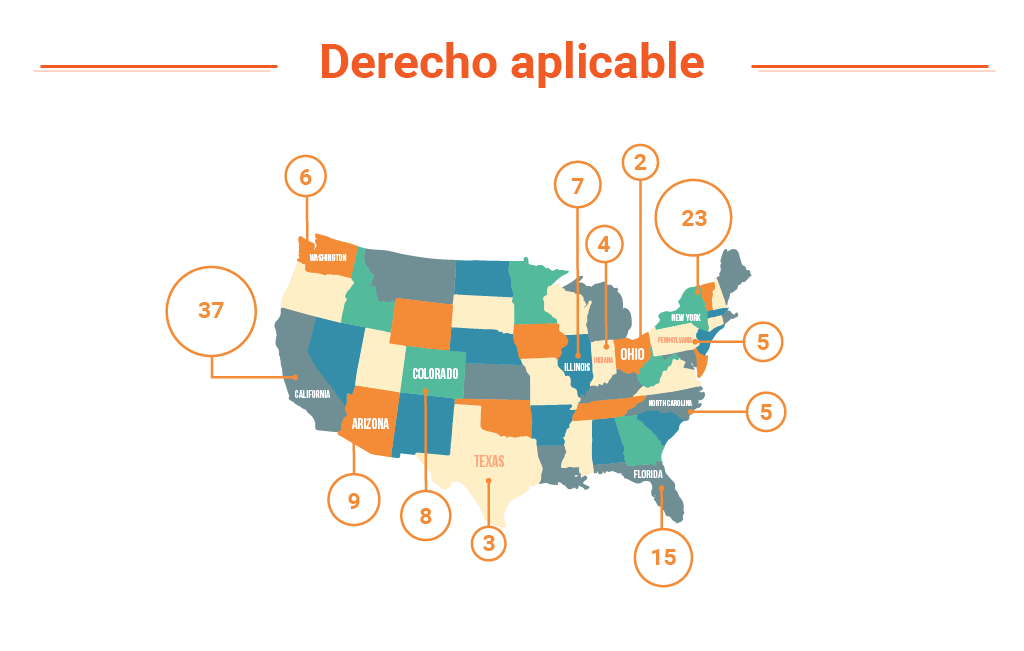
- En Derecho aplicable, extraer la jurisdicción cuyas leyes gobernarán la interpretación de los términos del contrato.
- Y así sucesivamente con otras cláusulas.
- Obtener insights valiosos del conjunto de documentos. Una vez analizados todos los documentos se pueden combinar los resultados individuales para obtener insights agregados que nos den una idea del conjunto, tales como los siguientes
- Gráfico por tipos de documento
- Tabla de cláusulas por contrato

- Gráfica de distribución de la duración
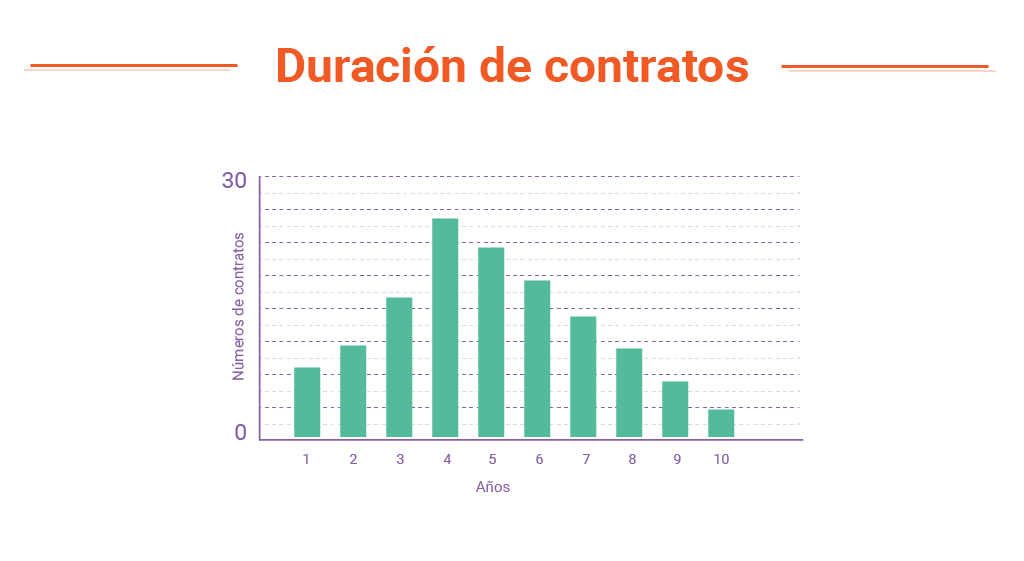
- Gráfica de distribución geográfica de la jurisdicción aplicable
- Gráfica de distribución de la cuantía de los daños y perjuicios
¿Qué necesitamos de una solución de Deep Semantic Analytics?
La tecnología permite hacer desarrollos a medida para extraer determinados datos de ciertos tipos de documentos. Pero cuando la variedad de datos y contextos es muy amplia y cuando la información se puede expresar de múltiples maneras esta solución se convierte en una pesadilla difícil de evolucionar y mantener. Si estás interesado en realizar Deep Semantics Analytics estas son las características que debería tener tu solución:
- Capacidad de analizar información en diversos formatos y presentaciones: texto, PDF, Word, formato libre, tablas
- Gran exactitud en la extracción de insights, con independencia del dominio de aplicación y de su lenguaje específico: legal, médico, económico…
- Flexibilidad en el tipo de insights a extraer (p.ej., relaciones entre accionistas, términos de indemnización) y productividad en la definición de estos, sin que sean necesarios entrenamientos masivos del sistema ni codificaciones de bajo nivel a medida
- Multiidioma: aunque el inglés sea la lengua de los negocios, noticias, memorias financieras, contratos, historiales clínicos siguen elaborándose en los idiomas de su países de origen
- Alta escalabilidad, disponibilidad y confidencialidad: debe poseer una arquitectura que garantice el crecimiento sin sobresaltos, el funcionamiento permanente y la seguridad de la información
- Mínimos costes y riesgo en su adopción: posibilidad de empezar a usarlo sin grandes inversiones, con modalidades flexibles de pago
- Time-to-benefit corto: minimizar el tiempo que va desde la comprensión de la necesidad hasta que la solución entrega resultados.
¿Interesado?
En MeaningCloud estamos desarrollando herramientas para Deep Semantic Analytics, que tenemos ya funcionando en beta en algunos clientes en diversos idiomas: español, inglés y otros. Si tienes un caso de uso donde necesitas extraer insights profundos de los documentos y te gustaría saber si te podemos ayudar no dejes de contactarnos en sales@meaningcloud.com.
