Una de las preguntas que más recibimos es cómo se pueden aplicar a casos particulares los servicios de analítica de texto de MeaningCloud.
Nuestros usuarios conocen los beneficios de la analítica de texto y quieren incorporarla en su flujo de trabajo, pero no están seguros de cómo canalizar sus necesidades empresariales a una solución que puedan integrar con facilidad. Si además se incluye el hecho de que cada proveedor denomina de manera diferente a los productos de analítica de texto, se convierte en una odisea no solo empezar a integrar estos productos en tu flujo de trabajo, sino también llegar a saber qué es lo que necesitas exactamente en tu caso.

En este post vamos a explicar para qué se utilizan nuestros productos, los tipos de procesamiento de lenguaje natural a los que van ligados, el valor añadido que estos ofrecen y las necesidades que cubren.
Topics Extraction
Topics Extraction, Extracción de Topics en español, es la solución de MeaningCloud para “extraer automáticamente información estructurada o semiestructurada desde documentos legibles por una computadora”[1]. En otras palabras, Topics Extraction extrae piezas de información específica de un texto o de un conjunto de textos, desde nombres propios hasta ubicaciones o cantidades de dinero.
Hay varias maneras de referirse a esta tarea: Named Entity Recognition, NER (por sus siglas en inglés), Reconocimiento de Entidades, etc., y todas ellas reciben su nombre por hacer referencia a la tarea de Topics Extraction por excelencia. Sin embargo, el objetivo es común: extraer información estructurada de un texto.
Tomemos como ejemplo el siguiente texto, sacado de un artículo del periódico digital eldiario.es:
Una copia de la tesis de Hawking puede venderse por más de 100.000 euros
Una copia firmada de la tesis del fallecido científico británico Stephen Hawking, escrita en 1965, puede venderse este mes por más de 100.000 libras (113.000 euros) en una subasta electrónica de la casa Christie’s de Londres.
El trabajo, titulado “Las propiedades de un Universo en expansión” y que escribió cuando tenía 24 años, provocó que el sitio de internet de la Universidad inglesa de Cambridge colapsara cuando fue publicado a través de la red en 2017.
Hawking, que padecía desde los 21 años esclerosis lateral amiotrófica (ELA), una enfermedad que lo dejó en silla de ruedas y le obligó a comunicarse a través de un sintetizador de voz, falleció el pasado 14 de marzo en Cambridge a los 76 años.
¿Cómo quedaría esta noticia periodística después de extraer su información utilizando nuestra API de Topics Extraction?

A primera vista podría parecer que se trata únicamente de encontrar los nombres propios que aparecen en el texto, pero eso no es todo. Hay varias maneras de referirse a la misma persona: con nombre y apellidos, solo por el apellido, con apodos, etc. En este caso, detectamos la persona protagonista del artículo dos veces, una como Stephen Hawking y otra como Hawking.
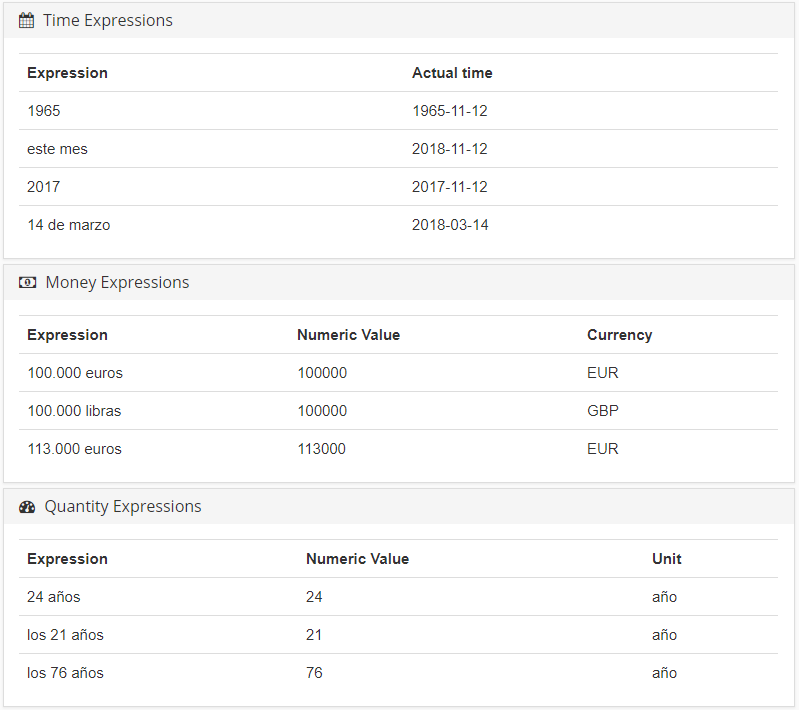
Además de nombres propios, y dependiendo del caso en particular, puede resultar interesante detectar otros tipos de información estructurada, como cantidades, fechas y palabras clave. La imagen de la derecha es un ejemplo de este tipo de salida.
No obstante, a veces, identificar las entidades presentes en el texto es más que suficiente. Para esos casos, las entidades tienen un tipo asociado, con lo cual es posible extraer únicamente ubicaciones, personas, organizaciones, etc. Puedes echar un vistazo a todos los tipos de entidades que detectamos en nuestra ontología.

También es posible definir tus propias entradas con su correspondiente tipología utilizando nuestras herramientas de personalización. Creando uno o más Diccionarios, podrás extraer las entidades y conceptos específicos de tu ámbito usando tu ontología personalizada.
Aquí hay algunos contextos en los que la solución de Topics Extraction se puede implementar:
- Sugerencias automáticas de etiquetas para noticias o entradas de blog.
- Para publicación semántica, es decir, como un marcado semántico que acompaña a los documentos y ayuda a comprender el significado del texto.
- Como herramienta para análisis de popularidad en función de las menciones de una entidad concreta.
- Como herramienta para la identificación de la información clave en la extracción de entidades.
Text Classification/Deep Categorization
Text Classification, o Clasificación de Texto, y Deep Categorization, o Categorización Profunda, son los productos de MeaningCloud para la clasificación o categorización de un documento. Se encargan de asignar una o más categorías predefinidas a un documento. A diferencia de Topics Extraction, en lugar de extraer información del texto, estas herramientas lo analizan y deciden dentro de qué categoría o categorías disponibles debería ser clasificado. En otras palabras, Text Classification y Deep Categorization nos proporcionan una idea de qué trata un texto de acuerdo con unos criterios específicos. Esta solución se puede aplicar a documentos de diversa longitud: un artículo periodístico, un tuit o el feedback que nos manda un cliente.
Esta funcionalidad presupone que haya una o varias categorías definidas de antemano, así como sus criterios de clasificación estipulados. En MeaningCloud, denominamos modelo de clasificación o de deep categorization al conjunto de categorías predefinidas y criterios —o reglas— que las determinan.
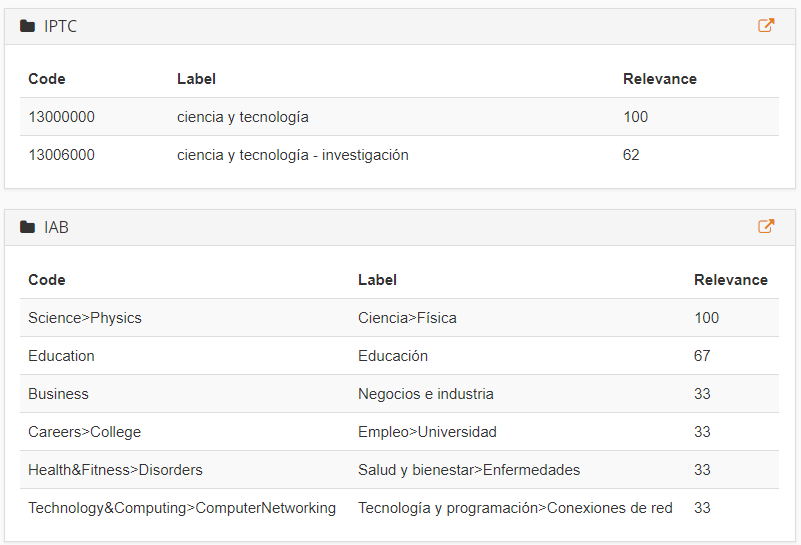
Nuestra API de Text Classification ofrece varios modelos de clasificación genéricos predefinidos como IAB (un estándar de la industria publicitaria) o IPTC (un estándar internacional para clasificación de noticias).
Las imágenes de la derecha muestran la salida dada por los modelos de clasificación IAB e IPTC teniendo el texto previo de ejemplo como entrada.
Por otro lado, nuestra API de Deep Categorization ofrece la última actualización del estándar IAB (su versión 2.0) además de incluir varios modelos de Voz del Cliente y Voz del Empleado.
¿Por qué se pueden emplear dos productos para implementar la misma funcionalidad? Respuesta corta: para optimizar su rendimiento y precisión. Respuesta larga: dependiendo del caso que te ocupe, el criterio necesario para definir las categorías puede diferir inmensamente. Las taxonomías muy amplias y heterogéneas no requieren criterios lingüísticos demasiado complejos y se apoyan en un motor con un componente estadístico sólido y potente. Estos dos elementos tienen un alto impacto en el rendimiento, dando lugar a excelentes resultados con grandes taxonomías. Esto es en lo que está centrada nuestra API de Text Classification.
Por otro lado, lo que pretendemos alcanzar con Deep Categorization es un nivel de análisis más preciso y detallado, cuyo potencial sale a relucir en contextos en donde las características lingüísticas más sutiles cobran protagonismo a la hora de categorizar textos. En estos casos es necesario tener en cuenta las sutilezas del lenguaje y, al mismo tiempo, acceder a toda la información del análisis morfosintáctico de MeaningCloud, que es exactamente lo que hace nuestra API de Deep Categorization. En los ejemplos mencionados anteriormente de Voz del Cliente y Voz del Empleado, es clave conocer las sutilezas lingüísticas, como por ejemplo el tiempo verbal en que hablan tanto el cliente como el empleado, ya que pueden cambiar el significado del texto.
En determinadas situaciones, este criterio genérico puede no satisfacer tus necesidades. Para esos casos es posible definir un modelo de clasificación propio a través de nuestra herramienta de personalización.
Algunos casos en los que se pueden aplicar las soluciones de Text Classification y Deep Categorization:
- Sugerencias automáticas para artículos de prensa o entradas de blog.
- Como herramienta para tener organizado, a golpe de vista, el feedback recibido.
Sentiment Analysis
Sentiment Analysis, o Análisis de Sentimiento, es el producto de MeaningCloud para el análisis de sentimiento o la minería de opinión. Este servicio se encarga de identificar y extraer información subjetiva de los recursos[2]. Una de las tareas más básicas del análisis de sentimiento es la clasificación de la polaridad de un texto. Esta clasificación puede llevarse a cabo bien a nivel global o de documento, bien a nivel parcial o de frase. Nuestra API de análisis del sentimiento combina un análisis morfosintáctico completo, realizado por el motor de MeaningCloud, incluyendo la polaridad asociada a cada elemento del texto, lo que nos permite extraer la información del sentimiento a todos los niveles.
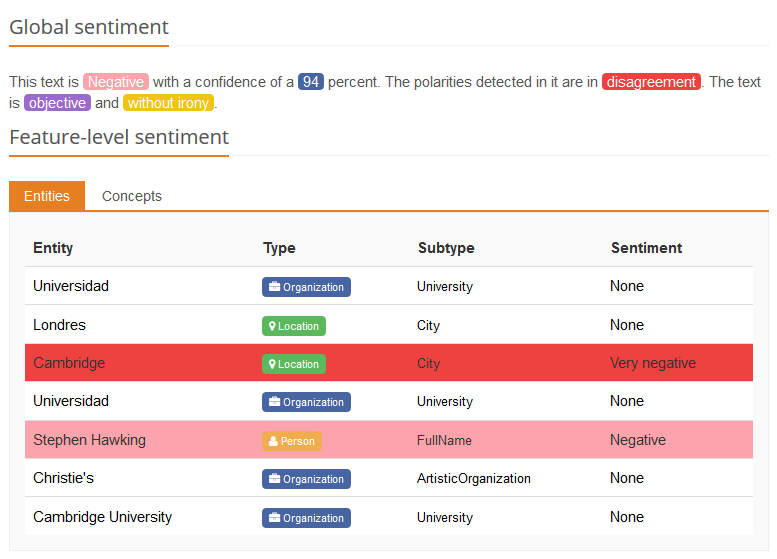
En la imagen se puede observar el análisis global del texto que hemos usado antes como ejemplo. La polaridad está ligada a (1) un grado de confianza, (2) un valor de acuerdo o desacuerdo entre las polaridades detectadas, (3) un valor de subjetividad u objetividad y (4) un valor de ironía.
MeaningCloud también posibilita la combinación del análisis de sentimiento con Topics Extraction, permitiendo así obtener la polaridad asociada a las entidades y conceptos detectados en el texto. Este ejercicio se suele denominar análisis de sentimiento a nivel de aspecto.
En la imagen de la derecha podemos ver algunas de las entidades detectadas. Las coloreadas en rojo se detectan con una polaridad negativa, mientras que las que no muestran ninguna polaridad permanecen en blanco.
Tal y como ocurre con los productos de los que hemos hablado antes, es posible personalizar la herramienta de Sentiment Analysis a través de nuestra consola de personalización. Esta consola permite la modificación el sentimiento asociado tanto a los términos como a las entidades y conceptos que se quieran analizar a nivel de aspecto.
Algunos de los casos en los que resulta útil utilizar Sentiment Analysis son:
- Para llevar a cabo análisis de reputación.
- Para analizar modelos de la Voz del Cliente o de la Voz del Empleado, donde se estudia la positividad o negatividad del feedback recibido.
Otros productos
Text Clustering
La herramienta de Text Clustering, o Clustering de Texto, se encarga de agrupar un conjunto de textos de tal manera que los textos de un mismo grupo sean más similares entre sí que con respecto a los textos de otro grupo[3].
Esta solución nos puede ayudar a encontrar patrones en los textos para luego ordenarlos y clasificarlos en función de su temática, o para averiguar nueva información sobre ellos y usarla como feedback para otros tipos de análisis.

En la imagen podemos ver el resultado que obtenemos si analizamos, a través de su API, el texto que hemos usado como ejemplo. Hay tres textos clasificados en dos temáticas diferentes: “Años” y “Hawking”.
Text Clustering se puede aplicar sobre los textos clasificados previamente por Text Classification, por ejemplo, para identificar nuevas categorías que añadir al modelo.
Language Identification
Language Identification, o Identificación de idioma, es el producto de MeaningCloud para determinar en qué idioma está escrito un texto. Aunque es una tarea que se puede concebir como auxiliar, no es baladí. Todas las herramientas previamente explicadas necesitan conocer el idioma del contenido que se va a analizar.
En el caso de que se esté trabajando con un solo idioma, esta tarea podría no resultar necesaria. Sin embargo, hoy en día los contextos multilingües como Twitter y las demás redes sociales están a la orden del día. Por esta razón, disponer de una API que lleve a cabo esta tarea automáticamente es extremadamente útil.
Lematización, PoS y Parsing
El servicio de Lematización, PoS y Parsing ofrece un análisis morfosintáctico completo de un texto:
- La lematización es la tarea por la cual, “dada una forma flexionada (por ejemplo, en plural, en femenino, etc.), halla el lema correspondiente”[4].
- El etiquetado PoS (sigla en inglés de Part of Speech) o etiquetado gramatical es “el proceso de asignar a cada una de las palabras de un texto su categoría gramatical”[5].
- El parsing o análisis sintáctico es el análisis de una serie de símbolos, tanto en lenguajes naturales como en lenguajes de programación, de acuerdo con las reglas de una gramática formal[6].
La imagen de la derecha es un árbol morfosintáctico de una de las oraciones del texto de ejemplo.
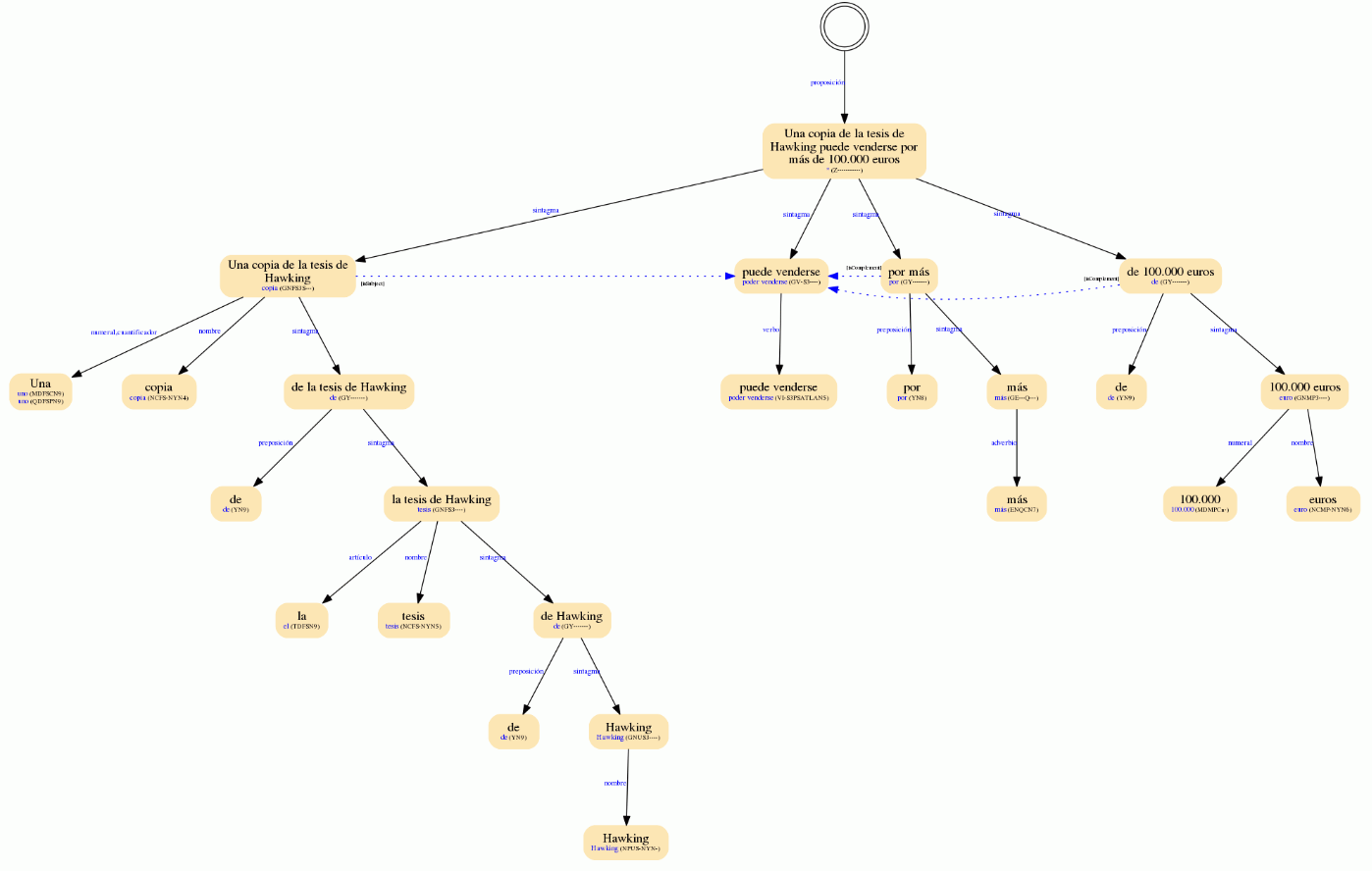
Los árboles morfosintácticos que ofrece esta API combinan la tecnología de Topics Extraction y la de Sentiment Analysis. Esta herramienta une el análisis del sentimiento con el análisis morfológico, sintáctico y semántico, lo cual se traduce en una salida de la API muy completa y con cierta complejidad que, a cambio, otorga un sinfín de posibilidades para el post-procesamiento, incluyendo la extracción de patrones.
Summarization
Summarization, o Resúmenes Automáticos, es el producto de MeaningCloud para acortar un documento y crear un resumen con sus ideas más importantes.
Esta tarea es una tarea clásica dentro del repertorio del Procesamiento del Lenguaje Natural, además de contar con numerosas aplicaciones. Esta funcionalidad puede plantearse de dos maneras diferentes: como resumen extractivo y como resumen abstractivo . En caso del resumen extractivo, este se crea exclusivamente a partir del contenido del documento original (como por ejemplo seleccionando las palabras u oraciones clave), mientras que un resumen abstractivo se crea desde cero. Nuestra API de Summarization realiza un resumen extractivo con el número de oraciones elegido.
Document Structure Analysis
Document Structure Analysis, o Análisis de la Estructura de Documentos, es el producto de MeaningCloud para examinar la disposición de un documento, como por ejemplo una página web o un texto con lenguaje de marcado estándar. Esta tarea ha ido ganando notoriedad debido a la creciente necesidad de procesar grandes documentos. Tratar este tipo de documentos puede ser una tarea muy tediosa, con lo cual es útil conocer de antemano su estructura para centrarse solamente en las partes en las que se está interesado. Esta es su API.
Corporate Reputation
Corporate Reputation, o Reputación Corporativa, no es una tarea habitual dentro de las tareas estándar del Procesamiento del Lenguaje Natural. Esta solución aúna la potencia de diferentes herramientas para centrarla en una salida específica con el objetivo de conocer la reputación u opinión sobre una empresa a partir de lo que se dice de ella.
Combinando Topics Extraction, Sentiment Analysis y Text Classification, la API de Corporate Reputation analiza el sentimiento y la polaridad asociados a las organizaciones mencionadas en un texto de acuerdo con las diferentes categorías predefinidas de un modelo de reputación.
Este es un pequeño resumen de nuestras principales herramientas, a las que puedes acceder a través de nuestras APIs o utilizando nuestras integraciones. Entre ellas destacan nuestro add-in para Excel, muy útil si no te apetece escribir código, nuestra integración para Zapier o nuestro nuevo Add-on para Google Sheets. Si tienes alguna pregunta sobre cómo se pueden aplicar estas tecnologías a tus necesidades, no dudes en escribirnos, estaremos encantados de ayudarte.

2 comentarios en “El abecé de la analítica de texto & MeaningCloud”
Muchas gracias por esta excelente introducción a terminología de Análisis de Datos!
¡Muchas gracias, Fernando! A veces la terminología puede ser confusa, así que nos alegramos de que este post te sea útil. Un saludo y gracias por comentar.